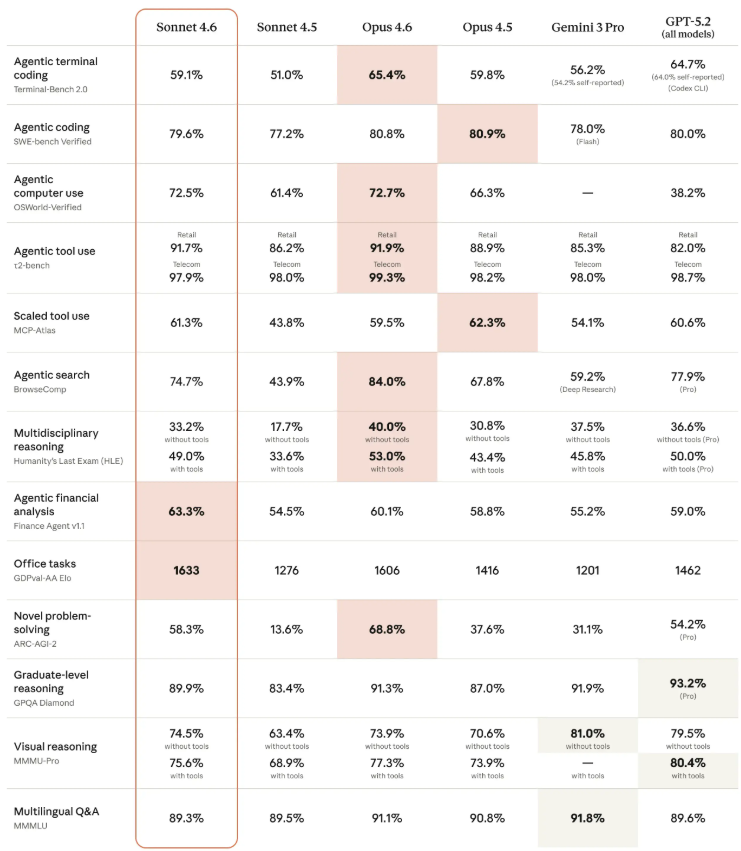
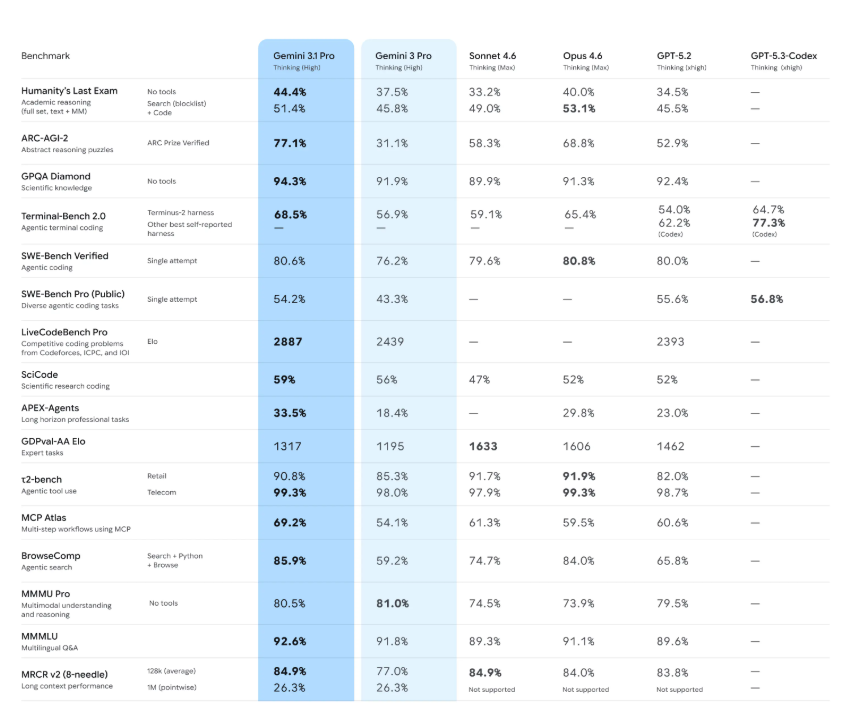
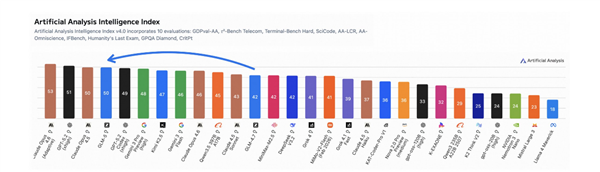
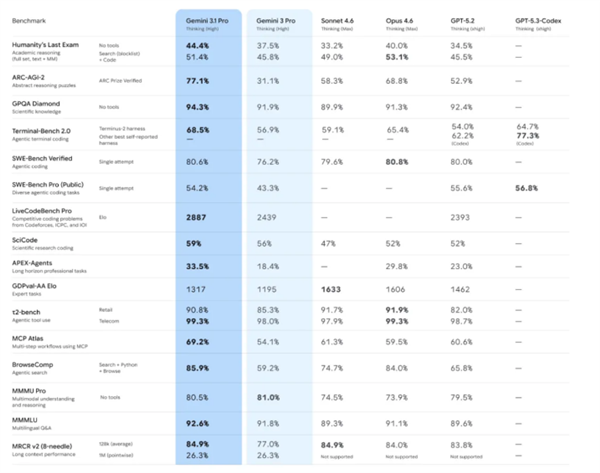
Inception Labs以Mercury2颠覆AI领域——一款像编辑一样思考的扩散模型
AI语言模型的新方法
人工智能初创公司Inception Labs通过新发布的Mercury2模型大胆地背离了行业常规。这个系统的特别之处不仅在于其性能——更在于其底层技术与当今大多数语言模型的根本性差异。

对文本生成的另类思考
当几乎所有主流语言模型都依赖Transformer架构(ChatGPT等系统背后的技术)时,Mercury2却从扩散模型中汲取灵感——这与许多图像生成工具采用的方法相同。这不仅仅是技术方案的替换;它改变了AI处理信息的方式。
想象传统AI写作就像有人在键盘上一个字母一个字母地输入。而Mercury2的工作方式更像一位经验丰富的编辑一次性审阅整部手稿。它不是顺序生成文本,而是可以同时评估和优化多个部分。
"这种并行处理为Mercury2带来了显著优势," Inception Labs首席科学家Elena Torres博士解释道,"在处理复杂推理任务或长文档时,我们的模型能在整个文本中保持上下文连贯性,而不是陷入线性推进的困境。"
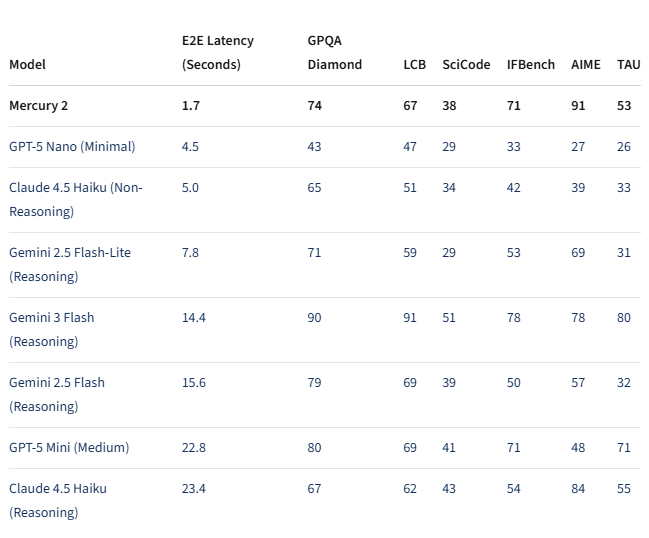
令人瞩目的速度
性能数据讲述了一个令人印象深刻的故事:
- 在NVIDIA Blackwell GPU上每秒生成1,009个token
- 端到端延迟仅1.7秒
- 速度超越Google的Gemini3Flash(快8倍)和Anthropic的Claude Haiku4.5等竞争对手
这种速度的提升并未以牺牲质量为代价。在包括GPQA Diamond和AIME(衡量推理能力的标准测试)在内的基准测试中,Mercury2与当今顶级轻量级模型不相上下。
为商业需求而打造
Inception Labs显然在设计Mercury2时就考虑了实际应用:
- 经济高效:价格仅为同类服务的约25%
- 企业级支持:支持128,000 token上下文和工具调用功能
- 专业化设计:特别适合响应时间至关重要的语音助手、搜索系统和编码工具
开发者现已可以通过API亲身体验这些功能。
关键要点:
- 🌀 架构革命:用扩散模型替代Transformer实现并行文本优化
- ⚡ 极速处理:每秒处理超过1K token且响应时间低于2秒
- 💰 经济实惠:价格仅为竞争对手的四分之一