Meta新工具可在AI训练崩溃前检测隐蔽的GPU故障
Meta攻克破坏AI训练的隐形GPU故障
随着人工智能模型规模呈指数级增长,支撑它们的GPU集群已成为有史以来最复杂——也最不稳定的计算系统之一。Meta的AI研究团队近日公布了针对行业最棘手问题之一的解决方案:那些可能导致昂贵训练任务数周心血白费的隐形硬件故障。
AI基础设施中的隐形威胁
想象花费200万美元训练AI模型时,中途却发现一块故障显卡污染了所有结果——这正是"隐形故障"的可怕之处:看似运行正常但性能已受损的GPU。与可简单增加容量的网页服务器不同,AI训练对这些细微硬件问题毫无招架之力。
"单个问题GPU就像在集群中蔓延的毒药",Meta技术文档解释道,"梯度值被污染后,可能要浪费数天乃至数周的计算才能发现问题。"
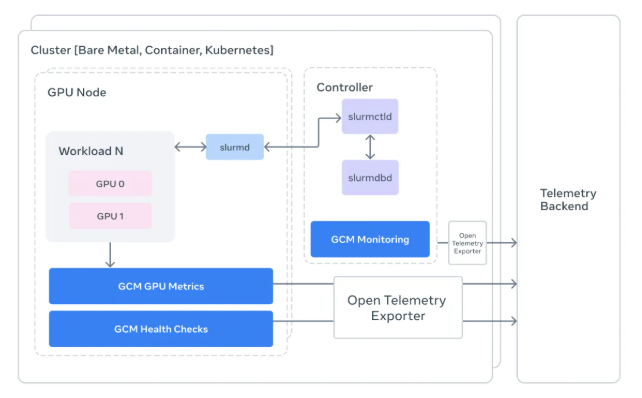
GCM的工作原理
新开源的GPU集群监控(GCM)工具包充当了原始硬件数据与需要可操作见解的工程师之间的翻译官。深度集成流行的Slurm调度器后,它能提供:
- 任务级可视化:工程师现在可以将功率波动或错误追溯至具体任务,而非猜测哪个节点可能有问题
- 自动化诊断:系统使用NVIDIA的DCGM工具在每项任务前后执行全面检查
- 直观仪表盘:复杂的遥测数据被转换为OpenTelemetry格式,可在Grafana中清晰查看
"使用GCM前发现这些问题如同大海捞针",一位熟悉该项目的Meta工程师表示,"现在我们相当于每天对每块GPU进行体检"
超越Meta的意义
在企业竞相训练更大模型的当下,这个时机再好不过:
- 当前训练任务通常需要数千块GPU持续工作数周
- 训练中断的成本随模型规模呈指数增长
- 传统监控工具并非为这类独特工作负载设计
通过开源GCM,Meta让中小机构也能获得过去科技巨头专属的监控能力。早期采用者反馈发现硬件问题的速度比传统方法快80%。
关键要点:
- 🕵️♂️ 检测隐秘故障:捕捉看似正常但性能低下的GPU
- 🔗 任务感知监控:将硬件指标直接关联到具体训练任务
- 💰 节省数百万:避免因训练数据污染导致的昂贵计算浪费
- 🚀 开源优势:让企业级监控能力惠及所有开发者

