美团LongCat-Next:新一代能像人类一样看、听、理解的AI
美团推出统一AI模型实现技术突破
美团推出的LongCat-Next模型能像处理文本一样自然地解析视觉与听觉信息,这一举措或将重新定义人工智能与世界交互的方式。这不仅是渐进式改进,更是AI同时理解多种数据类型的根本性变革。
工作原理:透过AI之眼观察世界
其核心DiNA(离散原生自回归)架构消除了不同数据类型间的人为壁垒:
- 一体化的处理系统:文本、图像和音频通过相同参数与机制的流程进行处理
- 理解与创造的统一:同一数学框架既处理理解任务(如阅读文本)也处理生成任务(如创建图像)
- 智能压缩技术:dNaViT视觉分词器可将高分辨率图像压缩28倍而不丢失关键细节,完美适用于复杂文档或财务报表分析
"这项技术的特别之处在于",一位熟悉该项目的美团工程师解释:"我们并非简单地为语言模型添加视觉功能。从底层设计开始,LongCat-Next就以统一方式处理所有信息。"
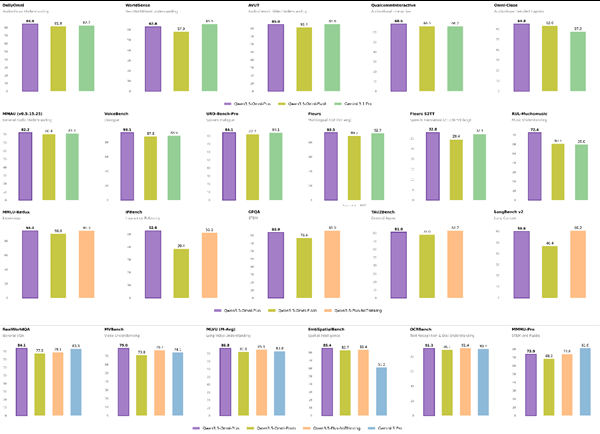
令专家惊叹的实际表现
该模型已展现出令人瞩目的能力:
- 在密集文本解析任务上超越专业文档分析工具
- 在视觉数学问题(MathVista)中获得83.1的高分,展现出多模态系统中罕见的逻辑推理能力
- 在保持顶尖语言理解能力的同时,还可生成具有可定制音色的语音
最令人惊讶的是,这些成果挑战了长期存在的认知——将连续数据(如图像)转换为离散标记必然导致质量下降。LongCat-Next证明通过这种方法不仅能保留信息,甚至还能增强信息。
对AI未来的重要意义
其影响远超出技术指标范畴。多年来,AI系统始终以语言为主要思维模式,难以真正整合其他感官。LongCat-Next预示的未来图景包括:
- 机器人可以像处理指令一样自然地导航空间
- 医疗AI能更直观地关联扫描影像与患者病史
- 创意工具可实现视觉与语言概念的无缝融合
美团已开源该模型及其分词器,邀请开发者共同探索这一新方法。正如一位研究者所言:"我们不仅在构建更好的AI工具——更在创造能像人类一样感知信息的系统。"
关键要点:
- 统一处理:首个通过相同机制原生处理文本、图像和语音的模型
- 性能验证:在文档分析和视觉推理任务中超越专用模型
- 开放访问:模型与分词器均可供开发者构建应用
- 未来潜力:有望推动跨行业实现更自然的人机交互