GPT-5.2在浏览器构建马拉松中超越Claude Opus
AI编程对决:GPT-5.2证明其工程实力
从零构建网页浏览器绝非儿戏——即使对先进AI系统也是如此。这项挑战需要解析HTML、渲染CSS布局、开发JavaScript虚拟机,同时保持数百万行代码的完美逻辑一致性。
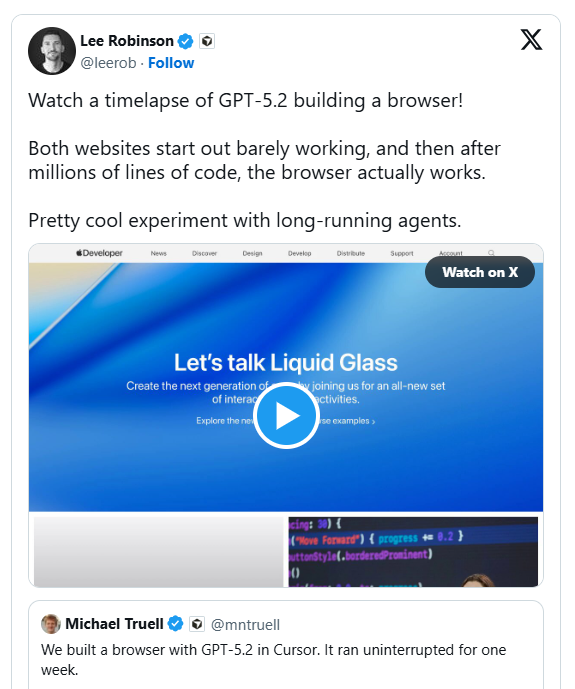
编程平台Cursor最近的内部测试显示,当两款领先AI模型被推向工程极限时存在显著差异。OpenAI的GPT-5.2在与Anthropic的Claude Opus 4.5长达数周的持续编程任务对决中成为明显赢家。
马拉松式测试
该实验并非编写快速代码片段,而是要求在整个软件开发周期保持专注:
- 持续项目推进需要架构规划和模块协调
- 自我修正早期设计缺陷而无需人工干预
- 多组件依赖管理
- 长期目标保持不出现"任务漂移"
"GPT-5.2能可靠地遵循复杂指令链,"Cursor团队报告指出,"在长时间推理过程中几乎不会偏离原始任务意图。"
Claude的不足之处
虽然Claude Opus 4.5在短时爆发中表现优异:
- 它倾向于提前终止复杂任务
- 频繁寻求简化方案而非应对完整复杂性
- 当挑战加剧时更常将控制权交还人类开发者
这种差异突显了当前AI模型处理"马拉松"与"冲刺"式编程挑战的关键区别。
超越浏览器构建
测试不仅限于浏览器:
- GPT-5.2成功复现了Windows 7模拟器
- 主导了包含百万行代码的遗留系统迁移
- 展示了自主规划架构和调试系统的能力
这些成就表明AI正从编码助手进化为具备端到端软件开发能力的潜在"数字工程师"。
影响深远——传统需要数月人类努力的工作可能很快由能在长期项目中保持惊人一致性的AI系统自主完成。
关键要点:
- GPT-5.2展现出对长期编程任务前所未有的耐力
- 在数周项目中比Claude Opus 4.5更能保持专注
- 成功构建完整浏览器并复现操作系统环境
- 标志着从编码助手向潜在自主工程师的转变
- 现已集成至Cursor平台供开发者使用