谷歌Gemini 2.5 Flash Lite现为最快专有AI模型
谷歌提升Gemini AI速度与效率
根据第三方评估,谷歌对其Gemini系列大语言模型(LLM)进行了重大更新,Gemini 2.5 Flash Lite现已成为可用的最快专有模型。
速度与性能提升
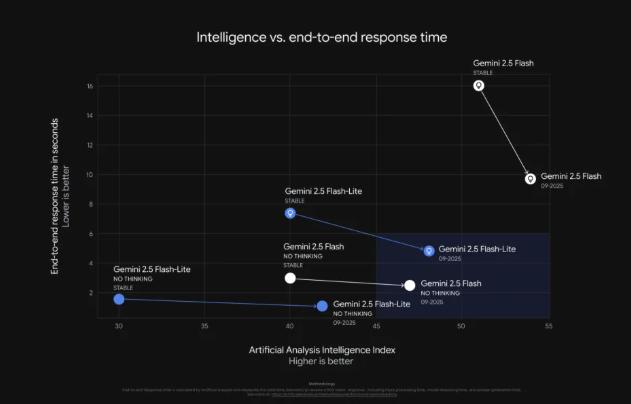
Artificial Analysis的独立分析证实,Gemini 2.5 Flash Lite可提供惊人的每秒887个token,比前代产品提速40%。虽然这仍低于MBZUAI和G42AI开源的K2Think模型所实现的每秒2000个token,但谷歌的专有产品仍具高度竞争力。
成本效率改进
最新更新聚焦于优化性能和运营成本:
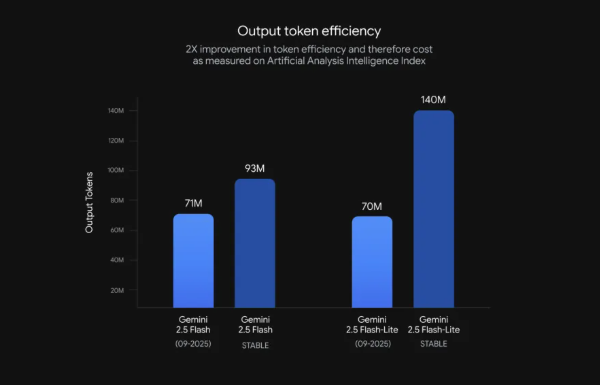
- Flash Lite将输出token减少50%,降低了高流量应用的部署费用
- 增强的指令遵循和多模态能力提高了响应质量
- Gemini 2.5 Flash在复杂工作流中表现优异,在SWE-Bench Verified基准测试中获得54%分数
面向开发者的增强功能
谷歌引入了新的模型别名以简化集成,同时保持向后兼容性。独立基准测试验证了多项性能指标的显著提升。
语音助手升级
此次更新不仅限于文本模型:
- Gemini Live(谷歌实时音频模型)针对语音应用进行了可靠性改进
- 增强的函数调用准确性实现了更自然的对话流程
- 开发者现在可通过新预览版获取这些升级功能
关键点:
- 🚀 Gemini 2.5 Flash Lite达887 token/秒——当前最快的专有模型
- 💰 50%的token缩减大幅降低运营成本
- 🗣️ Gemini Live改进支持更自然的语音交互体验
- 🔧 开发者友好型更新包含简化集成选项





