全球AI对决:海外模型领先,中国竞争者紧追不舍
中文AI模型在全球基准测试中交锋
人工智能领域迎来激动人心的进展——SuperCLUE发布了2025年度中文模型的全面评估。今年的竞赛汇集了全球23个参赛者,对它们进行了涵盖六大关键能力的严格测试。
海外巨头保持领先
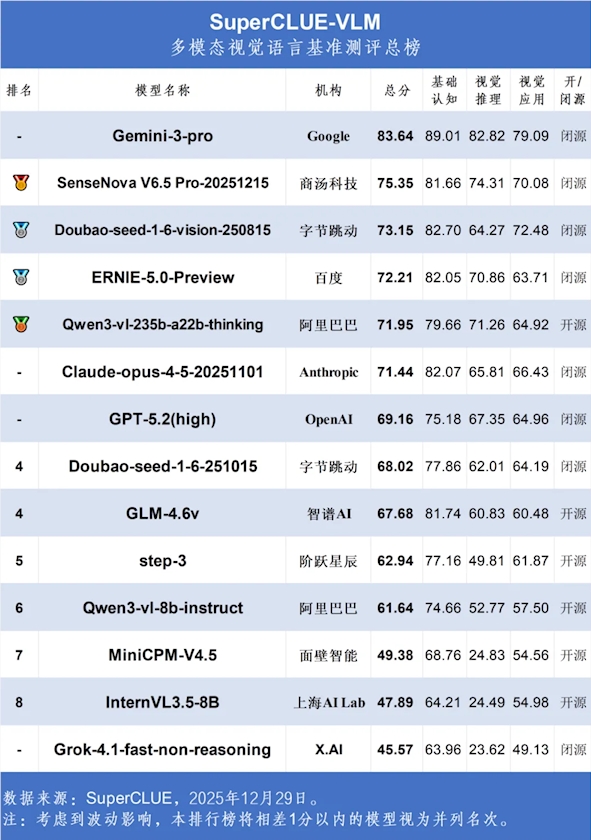
Anthropic的Claude-Opus-4.5-Reasoning以68.25分的成绩成为明显赢家,在推理任务中表现尤为突出。紧随其后的是Google的Gemini-3-Pro-Preview(65.59分)和OpenAI的GPT-5.2(64.32分),形成了全国际阵容的领奖台。
"这些结果证实了业内的普遍猜测,"清华大学AI研究员梁伟博士指出,"老牌企业仍在引领潮流,但每年的优势差距正在缩小。"
国内挑战者展现实力
真正的故事可能藏在排名靠后的位置——中国模型正开始挑战海外对手:
- Kimi-K2.5-Thinking(61.50分)获得总排名第四,同时以53.33分的最高分统治代码生成领域
- Qwen3-Max-Thinking(60.61分)在数学推理上与Google模型并列第一,均获80.87分
这些表现表明中国AI生态系统正从追赶阶段转向在特定领域成为真正竞争者。
专业优势显现
基准测试揭示了不同模型的显著优势:
- 代码生成:Kimi-K2.5-Thinking超越所有对手
- 数学推理:Qwen3-Max-Thinking与Google最佳产品平分秋色
- 科学推理:Claude-Opus保持传统优势
这一模式表明:虽然通用能力仍偏向国际模型,但中国替代品正在发展世界级的专业技能。
开源展现潜力
报告强调了另一个显著趋势——国内开源模型在该类别前五名中占据四席,暗示中国可能正在AI发展的重要细分领域开辟独特地位。
随着全球研发投资加速增长,这种快速进步引发疑问:当前领导者还能保持多久的优势?
关键要点:
- Anthropic的Claude以68.25分领跑总排名
- 中国模型在专业任务中展现特殊优势
- 国内开源替代品主导其所属类别
- 数学推理领域出现顶级竞争者间的惊人势均力敌