上海AI实验室发布首个视频转网页基准测试
上海AI实验室发布突破性视频转网页基准测试
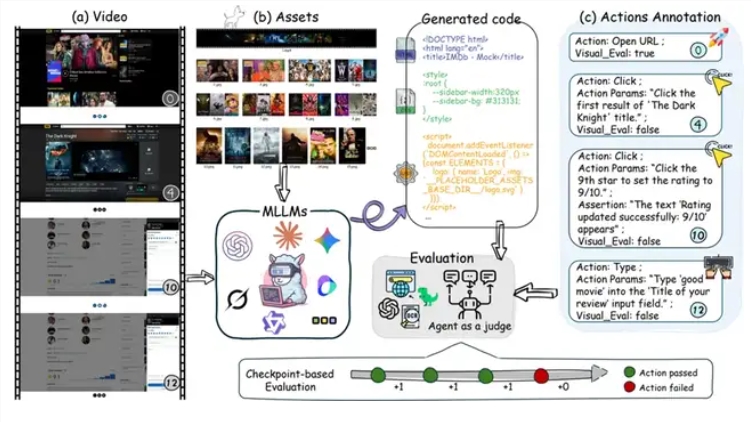
上海人工智能实验室推出了IWR-Bench,这是全球首个评估大型语言模型将视频演示转化为功能性网页代码能力的框架。这一创新性基准测试填补了评估多模态AI系统动态网页重建能力的关键空白。
AI评估领域的新突破
与传统图像转代码任务不同,IWR-Bench为模型提供了包含完整用户交互的视频以及所有必要的静态网页资源。该系统随后评估模型在不同复杂度级别(从基本网页浏览到2048游戏和航班预订系统等复杂应用)中重现观察到的动态行为的准确性。
揭示惊人的性能差距
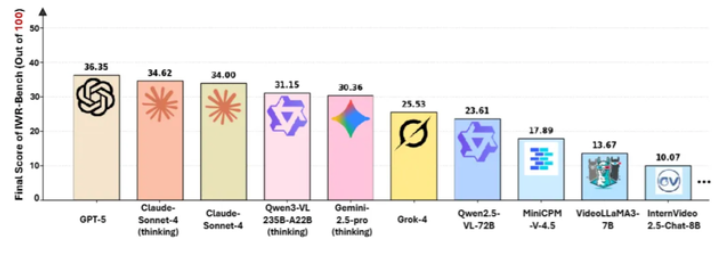
对28个领先AI模型的初步测试得出了令人清醒的结果:
- GPT-5以仅36.35/100的总分成为最佳表现者
- 交互功能得分(IFS):24.39%
- 视觉保真度得分(VFS):64.25%
视觉还原(64.25%)与功能准确性(24.39%)之间的显著差异凸显了将观察到的行为转化为有效代码逻辑的基本挑战。
创新的评估方法
该基准测试采用了多项新颖的评估技术:
- 基于代理的自动化测试验证交互功能
- 完整但匿名的静态资源迫使进行视觉匹配而非语义捷径
- 时间理解测试追踪视频帧间的状态变化
- 多维评分同时评估外观和功能性
发现的技术挑战
研究揭示了当前AI系统面临的四大障碍:
- 时间理解:从连续视频帧中提取关键事件
- 逻辑抽象:将行为转化为事件监听器等编程概念
- 资源匹配:正确将匿名文件与视觉元素关联
- 代码生成:生成结构良好的HTML/CSS/JavaScript
研究结果表明,即使是先进的多模态模型也难以应对动态网页重建所需的因果推理和状态管理。

行业影响
基准测试创建者强调了其双重意义:
- 研究价值:为评估动态理解能力提供新指标
- 实用潜力:技术成熟后可能降低前端开发门槛 然而研究人员警告称,高基准分数不会立即转化为生产就绪工具,并指出在处理性能优化、安全性和边缘案例方面存在关键差距。
关键点:
- 首个针对视频转网页的专业基准测试问世
- GPT-5领先但总分仅为36.35/100
- 模型显示强视觉还原能力(64%)但弱交互逻辑(24%)
- 揭示时间推理和状态管理方面的根本性差距
- 可能塑造未来"所见即所得"的开发工具