Gemini-3-Pro领跑多模态AI竞赛,中国模型实力崛起
多模态AI对决:谁在视觉-语言竞赛中领先?
随着2025年12月SuperCLUE-VLM排行榜的发布,多模态人工智能领域的霸主之争出现了有趣转折。这些评估衡量了AI系统理解和推理视觉信息的能力——在机器日益频繁地与图像丰富的数字世界互动的当下,这成为关键能力。
明显领先者
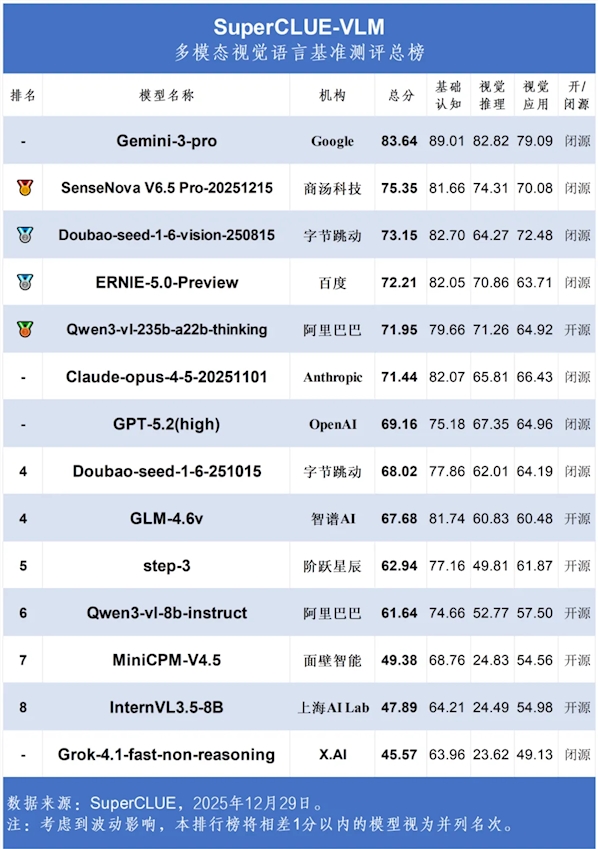
谷歌Gemini-3-Pro以83.64的总分持续保持统治地位,将竞争对手远远甩在身后。其在基础图像理解方面表现尤为突出(89.01分),但即便是这位领跑者,在视觉推理(82.82)和应用任务(79.09)方面仍有提升空间。
"Gemini脱颖而出的不仅是原始分数,"清华大学AI研究员赵林博士解释道,"而是其所有测试类别中的稳定表现——其他模型可能在特定领域出色但在其他地方表现欠佳。"
中国崛起新星
真正的亮点或许是中国技术的快速进步:
- 商汤SenseNova V6.5Pro以75.35分位居第二
- 字节跳动豆包以73.15分位列第三令人印象深刻
- 阿里巴巴Qwen3-VL作为首个突破70分的开源模型创造历史
这些结果表明中国科技公司正优先发展特别适合本土需求的能力——比如分析社交媒体图像或短视频内容。
意外与挫折
排行榜出现了一些令人惊讶的结果:
备受期待的OpenAI GPT-5.2尽管配置高端却仅获69.16分,引发对其多模态发展优先级的质疑。
与此同时,Anthropic的Claude-opus-4-5保持稳定表现(71.44分),延续了其在语言理解能力方面的良好声誉。
分数背后的意义
SuperCLUE-VLM测试评估三项关键能力:
- 基础认知: AI能否识别物体和文字?
- 视觉推理: 是否能理解关系和上下文?
- 应用能力: 能否执行如回答图像相关问题等实际任务?
结果揭示了进展最快和挑战仍存的领域: "我们看到基础识别方面取得了惊人进步,"赵博士指出,"但高阶推理能力仍是区分顶尖模型的关键因素。" 开源模型Qwen3-VL的强劲表现为强大多模态工具的普及铺平道路,而像豆包这样的商业模型则证明了针对特定用例的专业训练能带来显著成效。
关键要点:
- 谷歌保持领先但中国模型正快速缩小差距
- 开源方案现已能与专有系统竞争
- 视觉推理仍是所有平台面临的最大挑战
- 不同应用场景表现差异显著——目前尚无万能解决方案