Cohere以开源语音模型挑战AI巨头
Cohere以开源边缘模型颠覆语音AI
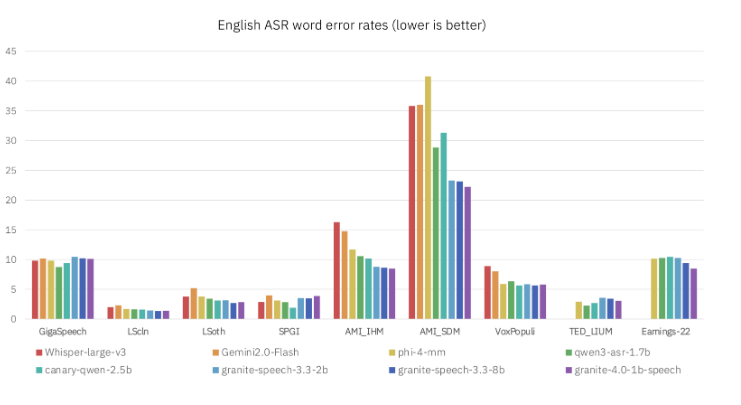
在向行业领导者发起的挑战中,AI公司Cohere于3月26日发布了Transcribe——这个异常敏捷的语音识别模型可能改变我们与设备的交互方式。仅凭20亿参数(远少于典型模型),Transcribe在保持高精度的同时足够小巧,可直接在智能手机和工业硬件上运行。
打破云端依赖
Transcribe的独特之处?它解决了语音AI最棘手的难题之一:延迟。传统模型需要持续云端连接,导致延迟和隐私问题。Cohere的解决方案在本地处理语音,提供:
- 更快的响应速度 适用于实时应用
- 增强的隐私保护 适用于医疗和金融等敏感领域
- 降低基础设施成本 通过减少云计算需求
"我们看到对离线AI的需求正在增长",行业分析师Maria Chen指出,"Cohere的时机恰到好处。"
令人惊讶的多语言表现
该模型支持包括中文、日语和希伯来语在内的14种语言——对于其紧凑体积而言堪称壮举。独立基准测试显示其准确度超越阿里巴巴Qwen3等成熟竞品。他们如何实现这一突破?Cohere工程师专注于优化神经网络效率而非简单堆叠参数。
智能体战争中的战略布局
此次发布标志着Cohere从文本生成首次重大跨入语音识别领域——这是AI助手进化过程中的关键能力。公司计划将Transcribe整合至其North平台,将其定位为构建智能体的完整解决方案。
采用Apache 2.0许可证的开源策略效仿了Meta的成功经验,既吸引开发者创新,又确立Cohere作为对抗IBM、Zoom等企业AI供应商的有力竞争者地位。
关键要点:
- 轻量化设计:20亿参数模型高效运行于边缘设备
- 语言支持:覆盖14种语言并保持领先准确度
- 开放生态:Apache 2.0许可证促进社区开发
- 战略扩张:与Cohere现有文本AI优势形成互补