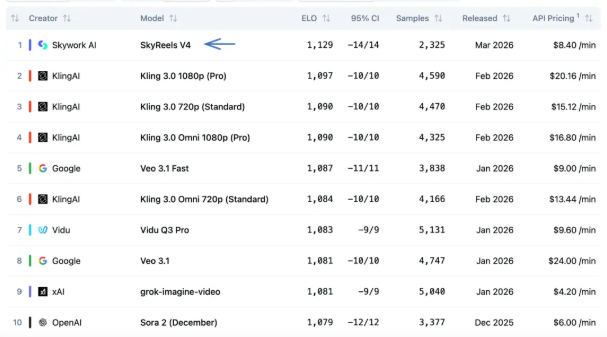
中国AI重大突破:Emu3.5模型可预测现实世界下一步发展
中国研究人员开发出能预判现实的AI
北京智源人工智能研究院在创造理解物理世界的人工智能方面迈出了重要一步。他们最新发布的Emu3.5模型超越了简单的内容生成,能够预测情境将如何演变。

图片来源说明:该图片由AI生成,图片授权服务提供商为Midjourney。
为何先前AI模型存在不足
传统AI系统擅长创建逼真图像或连贯文本,但缺乏根本性理解。"这些模型孤立地处理每一帧画面或句子,"项目首席研究员李伟博士解释道,"它们可能生成一个苹果下落的逼真图像,但无法预测它会落在哪里或发出什么声音。"
研究团队认为这种局限性源于模型的学习方式——关注表面模式而非底层物理规律。
Emu3.5如何改变游戏规则
这一突破来自将所有输入——无论是文本、图像还是视频帧——视为同一基础现实的不同表达:
- 取代独立处理流程,所有内容都转换为通用"标记"
- 模型持续提出一个问题:"接下来会发生什么?"
- 这种方法捕捉了视觉变化与语言演变之间的关系
"就像通过让人预测球的轨迹来教授物理知识一样,"李博士说,"通过数百万次预测,模型建立起对事物如何相互作用的隐含理解。"
实际应用前景显现
早期演示在多个领域展现出潜力:
- 机器人技术:预测物体互动可使机器人更擅长操作物体
- 自动驾驶汽车:模拟潜在交通场景能改善决策能力
- 内容创作:生成具有一致物理规律而非不连贯帧的视频
研究界认为这标志着焦点从更大模型转向更智能模型的转变。"参数很重要,"斯坦福大学AI研究员Mark Chen指出,"但真正的智能需要理解事情为何发生,而不仅仅是它们看起来什么样。"
智源团队计划在下个月的机器学习国际会议上发布技术细节。
关键要点:
- 统一建模:Emu3.5将所有数据类型视为世界状态的表达
- 预测导向:持续预判跨模态的后续发展
- 实际影响:在机器人技术、模拟和内容创作中的潜在应用
- 范式转变:代表从生成式AI向全面世界建模的转变