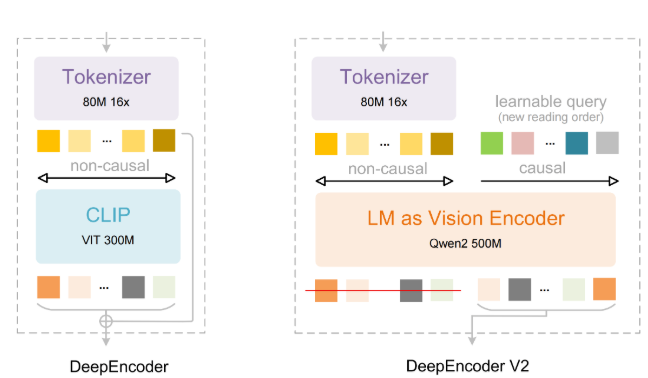
MIT自动化'运动工厂'赋予AI物理直觉
教会机器理解物理
是否曾观看体育回放时疑惑:为何AI解说员会搞错基础物理?当前视频分析系统能描述事件表象,但在涉及运动原理时就会出错——比如判断汽车是否闯过红灯,或预测球的落点。

核心问题在于数据。训练AI理解运动需要海量精确标注的时空运动样本。此前创建这种"运动参考数据"需人工逐帧标注,工作量极其繁重。
自动化解决方案
MIT、NVIDIA与加州大学伯克利分校的联合团队开发了FoundationMotion,他们称之为"自动化运动数据工厂"。该系统分三个阶段无缝运作:
- 突破性追踪技术: 先进算法跟随视频帧中的物体,将其运动转化为精确时空坐标
- 从数字到语义: 这些坐标被转换为丰富文本描述,不仅记录位置还包括速度、方向及物体间关系
- 自检质量: 系统自动验证输出结果后,将其打包为即用型问答训练对
惊人成效
当研究人员测试FoundationMotion的输出时取得突破:一个相对轻量的150亿参数模型使用该合成数据训练后,在运动理解任务中达到90.6%准确率——超越更大规模的开源模型(720亿参数)和商业系统。
"这证明质量胜过数量,"研究员解释道,"使用干净且物理准确的训练数据时,小模型能比接受噪声现实数据的大模型发展出更好的直觉。"
影响远不止体育分析。自动驾驶车辆可更准确预判行人动向,仓储机器人能与人类同事更流畅协作,甚至虚拟助手讨论视觉场景时也能获得空间感知能力。
未来展望
尽管成果显著,团队承认存在局限。当前系统最擅长处理简单物理交互——流体力学等复杂现象仍是挑战。但FoundationMotion标志着向研究人员所称"具备物理常识的具身技术"迈出关键一步。
正如团队成员所言:"我们不再只是教计算机看见——而是在教它们理解所见之物。"
核心要点:
- 自动化数据生成: 消除昂贵人工运动标注需求
- 物理直觉培养: 帮助AI系统掌握轨迹与时机等概念
- 效能提升: 接受高质量合成数据训练的小模型表现优于大模型
- 现实影响: 在自动驾驶、机器人及增强现实领域的潜在应用