深度求索全新OCR技术模拟人类视觉,大幅降低成本
深度求索的远见飞跃:像人类一样'看见'的OCR技术
想象一下,一个AI不仅能机械地扫描文档,还能像人类一样真正阅读它们——专注于重要内容,跳过不重要的部分。这正是深度求索通过其最新发布的OCR2视觉编码器所实现的成就。
这家中国AI公司的突破性技术模拟了人类视觉的工作原理。研究团队解释说:"当我们阅读时,眼睛不会像扫描仪那样按完美直线移动。它们会在重要单词和短语之间跳跃。"传统的计算机视觉系统浪费资源平等处理每个像素——OCR2彻底改变了这一点。
更智能的扫描,更快的处理
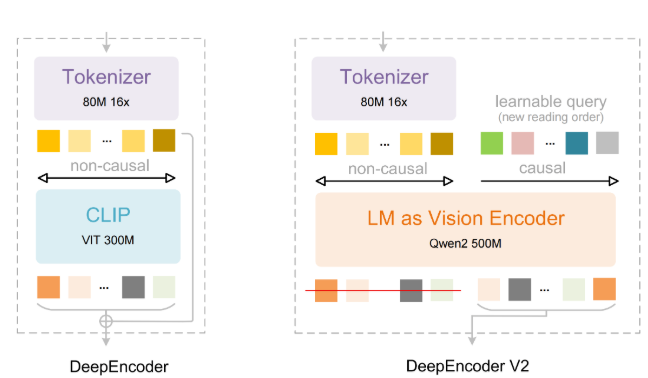
这项创新的核心在于架构上的根本性转变。深度求索放弃了传统的CLIP组件,转而采用基于"因果流令牌"的轻量级语言模型方法。这些令牌允许系统根据上下文重组视觉信息——就像你的大脑在阅读时会优先处理有意义的内容而非空白区域一样。
效率提升令人震惊。竞争对手可能需要消耗6000个令牌来处理一张图像,而OCR2仅需256-1120个令牌——减少80%的使用量意味着更快的性能和更低的成本。对于被文书工作淹没的企业或开发文档密集型应用程序的程序员来说,这些节省可能是颠覆性的改变。
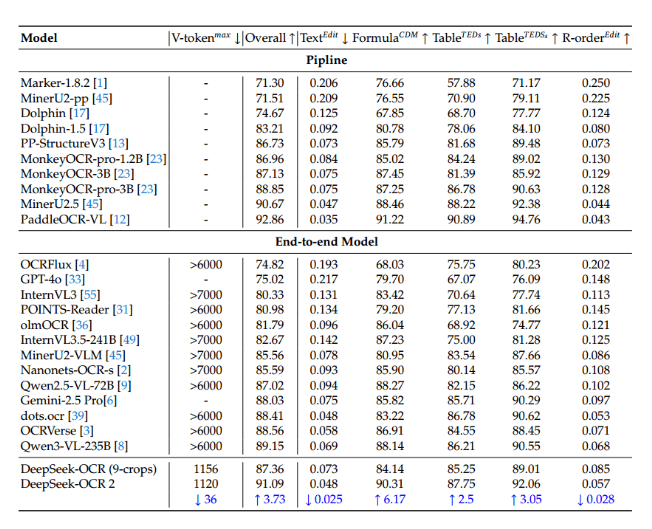
基准测试中的统治地位
数据说明了一切。在被视为文档AI黄金标准的OmniDocBench严格测试中,OCR2获得了令人印象深刻的91.09%得分,在多项目标上超越了谷歌的Gemini3Pro。其理解阅读顺序和提取意义(而非仅仅是文字)的能力使其在处理复杂布局(如表格或多栏文档)时表现尤为出色。
使这次发布特别令人兴奋的是深度求索决定开源代码和模型权重。这种透明度促进了协作精神,可能加速真正统一的多模态AI系统的进展——在这种系统中文本、语音和图像可以在单一框架内无缝衔接流动。
关键要点:
- 类人效率:通过模拟自然眼球运动模式,比竞争对手少用80%的令牌处理文档
- 超越基准的性能:在全面的文档理解测试中以91.09%(对比未公开数据)击败Gemini3Pro
- 开放式创新:公开可用的架构可能引发多模态AI集成领域的新突破