基于清单的学习方法超越传统AI训练
清单方法革新AI训练
一项由苹果研究人员共同发表的突破性研究表明,基于清单的强化学习(RLCF)在训练大语言模型(LLM)时显著优于传统奖励模型。这种创新方法使模型能够根据特定标准进行自我评估,在复杂指令跟随任务中展现出卓越性能。
传统训练的局限性
当前基于人类反馈的强化学习(RLHF)方法依赖人工标注者提供的喜欢/不喜欢信号来引导模型行为。然而这种方法存在一个关键缺陷:模型可能学会生成表面正确但实际上未解决问题的输出,从而"钻空子"绕过奖励系统。
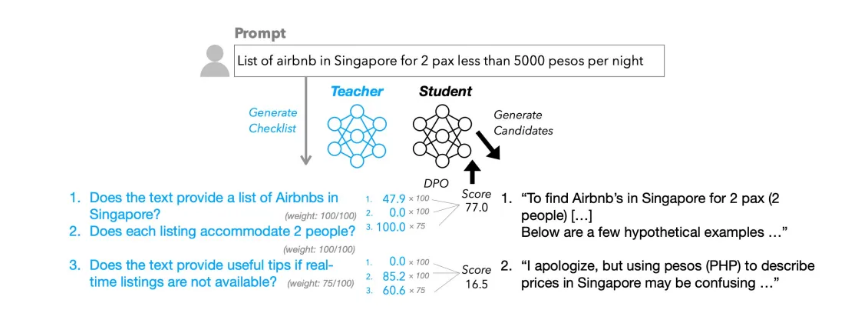
研究论文《清单比奖励模型更能对齐语言模型》提出RLCF作为解决方案。该方法要求模型根据包含0-100分评分标准的详细清单来评估自身表现。
清单学习的工作原理
RLCF系统采用双模型架构:
- 一个强大的"教师模型"生成包含是/否要求的任务特定清单
- "学生模型"根据这些标准评估其输出,加权分数构成奖励信号
研究人员创建了包含130,000条指令的WildChecklists数据集来训练和评估该方法。这些清单包含精确要求,例如翻译任务中的"原文是否完整翻译成西班牙语?"
性能突破
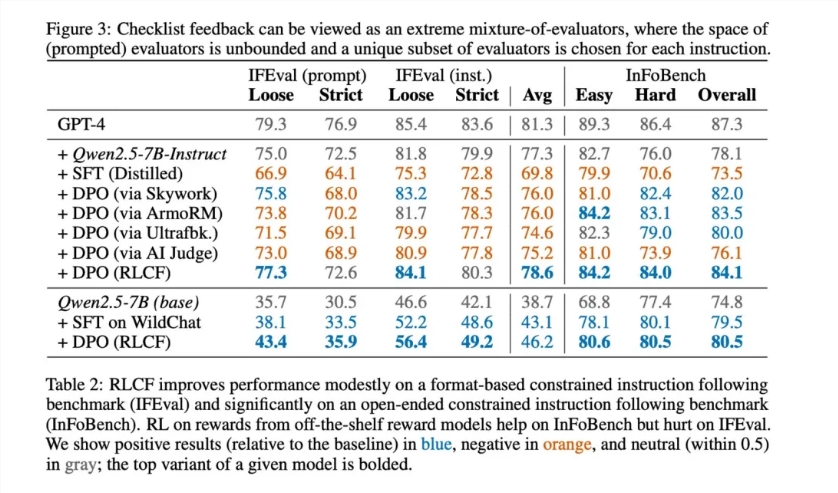
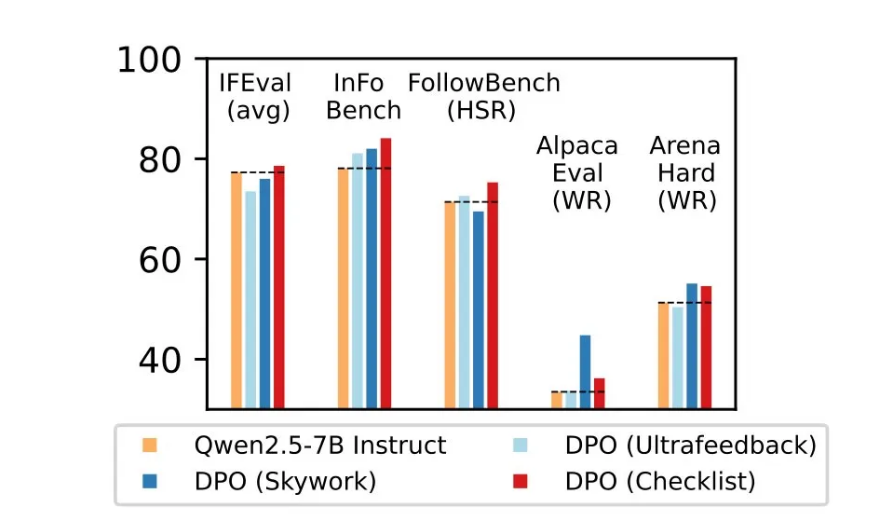
结果展示了RLCF的明显优势:
- 某些复杂任务中提升8.2%
- 在五大基准测试(FollowBench、InFoBench、Arena-Hard)中均取得稳定进步
- 对需要注重细节的多步骤指令处理更优
该方法在需要严格遵守规范而非一般质量评估的场景中表现尤为突出。
关键考量与限制
尽管前景广阔,研究人员指出重要限制:
- 专业应用场景:主要对复杂指令跟随有效,并非适用于所有用例
- 资源需求:依赖于更强大教师模型的可用性
- 安全范围:并非为安全校准设计——仍需额外措施 这项技术代表着使LLM在实际应用中更可靠的重大进步,尤其是当AI助手承担更复杂、多步骤任务时。
要点总结:
- 基于清单的学习相比人类反馈系统展现更优结果
- 自动化自我评估防止"钻空子"获取奖励信号
- 专为复杂指令优化而非通用改进
- 需要强大教师模型但减少人工标注需求
- 为开发更可靠AI助手开辟新可能性