阿里巴巴与南开大学联合推出LLaVA-Scissor视频模型压缩技术
阿里巴巴与南开大学推出LLaVA-Scissor实现高效视频处理
在重要合作中,阿里巴巴通义实验室与南开大学计算机学院联合发布了创新压缩技术LLaVA-Scissor,旨在优化视频大模型处理。这一发展解决了视频AI中的关键挑战,特别是传统方法因生成过多令牌导致的效率低下问题。
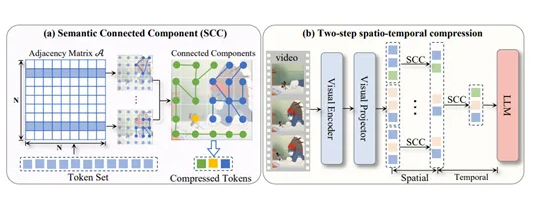
视频模型处理的挑战
传统视频模型需要对每帧单独编码,导致令牌数量呈指数增长。虽然现有压缩方法如FastV、VisionZip和PLLaVA在图像处理中表现良好,但由于语义覆盖不足和时间冗余问题,它们在视频应用中仍有局限。
LLaVA-Scissor的工作原理
新技术采用了基于图论的算法——SCC(相似性连通组件)方法。该方案:
- 计算令牌相似度
- 构建相似性图谱
- 识别图谱中的连通组件
每个组件的令牌可由单个代表令牌表示,从而大幅减少总数而不丢失关键信息。
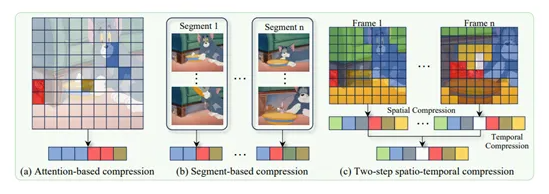
两步时空压缩策略
LLaVA-Scissor实施了精密的双阶段方案:
- 空间压缩:识别单帧内的语义区域
- 时间压缩:消除多帧间的冗余信息
该策略确保最终令牌集能高效代表整个视频内容。
基准测试亮点表现
该技术在多项测试中展现出卓越成果:
- 在50%令牌保留率下匹配原始模型性能
- 在35%和10%保留率下超越竞争对手
- 以35%保留率在EgoSchema数据集上达到57.94%准确率
这项创新在长视频理解任务中表现尤为突出,满足了行业关键需求。
未来影响
LLaVA-Scissor的开发不仅是效率提升——它还为以下领域开辟了新可能:
- 实时视频分析应用
- 降低计算资源需求
- 增强大规模视频处理系统的可扩展性
产学合作孕育的这一解决方案或将重塑视频AI发展格局。
关键要点:
- 🚀 效率突破:大幅减少令牌数同时保持准确性
- 🔬 创新算法:SCC方法实现智能语义保留
- 📈 性能验证:在低保留率下优于现有方法
- 🎯 实际应用:提供更具扩展性的视频处理方案




