微软研究发现:AI聊天机器人在长对话中准确率下降39%
微软与Salesforce的一项突破性研究揭露了当今最先进AI语言模型的关键缺陷:它们在长对话中维持准确性的能力会显著下降。研究表明,当用户通过多次交流逐步澄清需求时,系统性能会惊人地下降39%。
测试揭示惊人性能差距
研究团队开发了一种创新的"分片"测试方法,模拟用户逐步完善请求的真实对话场景。与传统单次提示评估不同,该方法将任务分解为连续步骤——真实反映人们与AI助手交互的方式。
结果令研究人员震惊。所有测试系统的模型准确率从约90%骤降至仅51%。这一下降趋势影响所有被评估模型,从Llama-3.1-8B等紧凑型开源方案到GPT-4o等行业领先的商业系统。
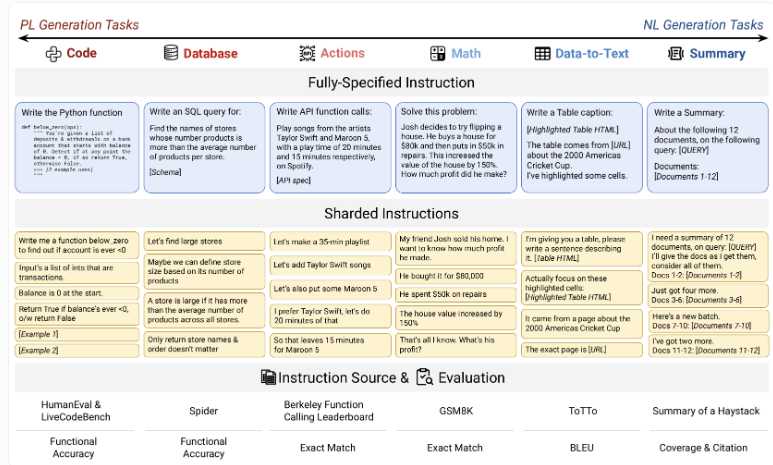
每项测试包含90-120条指令,使用高质量数据集分解为子任务,创造了严格的评估条件。
顶尖模型同样表现不佳
研究中评分最高的模型——Claude3.7Sonnet、Gemini2.5Pro和GPT-4.1——在多轮对话中均显示出30-40%的性能下降(相比单次交互)。更令人担忧的是它们的极端不稳定性,相同任务中的表现波动高达50个百分点。
识别四大关键故障模式
研究人员确定了导致AI模型在长对话中出现问题的四个根本原因:
- 仓促判断:模型常在收集完整信息前就得出结论
- 历史依赖:过度依赖早期回应(即使明显错误)
- 选择性注意:随着对话推进遗漏关键细节
- 信息过载:过多细节导致对缺失信息的混淆
技术修复收效甚微
团队尝试了多种技术解决方案:
- 降低模型"温度"以减少随机性
- 让AI重复指令以确保清晰度
- 调整每一步的信息密度
均未产生实质改善。唯一可靠的解决方式?预先提供所有必要细节——但这违背了对话式AI的初衷。
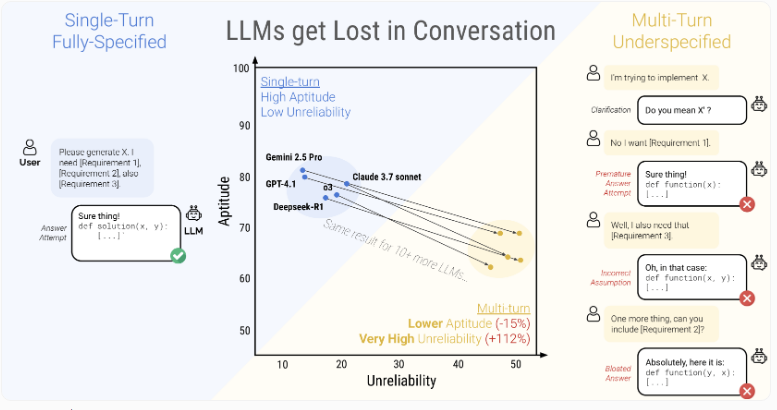
研究表明大型语言模型在多步对话中经常"偏离主线",导致性能急剧下降。
能力与可靠性的鸿沟
数据显示两个独立的故障层面:基础能力仅下降16%,但不可靠性却激增112%。虽然更强模型通常在单任务上表现更好,但在长对话中所有模型都会退化到相似的糟糕水平(无论其基准能力如何)。
实用建议浮出水面
研究结果提出了具体策略: 对用户建议:
- 当对话偏离轨道时重启而非尝试纠正
- 要求生成聊天总结作为新的起点 对开发者建议:
- 优先保障多轮对话系统的可靠性
构建能原生处理不完整指令的模型(无需提示工程技巧)
这对正竞相在客服、医疗和教育领域部署AI助手的行业影响深远。正如一位研究者指出:"可靠性不仅是指标——它决定了这些系统是创造真实价值还是徒增挫败感的基础。" 关键要点
- AI模型在渐进式对话中的准确率比单次交互低39%
- 所有测试系统(包括顶级商业模型)都表现出相似的可靠性问题
- 四大核心问题导致崩溃:过早结论、历史依赖、信息忽视和细节过量
- 技术优化效果有限;预先提供完整信息仍是唯一可靠方案
- 研究发现凸显了现实世界AI助手部署的关键挑战