使用 Diffusion-Vas 的视频对象跟踪进展
使用 Diffusion-Vas 的视频对象跟踪进展
在 视频分析 领域,理解对象的持续存在对识别它们的存在至关重要,即使它们完全被遮挡。传统对象分割技术主要关注可见(模态)对象,往往忽视了对 非模态(可见和不可见)对象的处理。
为了应对这一重大局限,研究人员提出了一种 两阶段方法,称为 Diffusion-Vas。这种创新方法旨在增强视频中非模态分割和内容补全的性能。该方法允许在视频序列中跟踪特定目标,采用扩散模型填充被遮挡区域。
方法论
第一阶段:生成非模态掩码
Diffusion-Vas 方法的初始阶段涉及为视频对象生成非模态掩码。研究人员通过将可见掩码序列与 伪深度图 合并,推断出对象边界的遮挡。这些图是通过对 RGB 视频序列的单眼深度估计得出的。此阶段的目标是识别可能被遮挡的对象部分,从而延伸对象的完整轮廓。
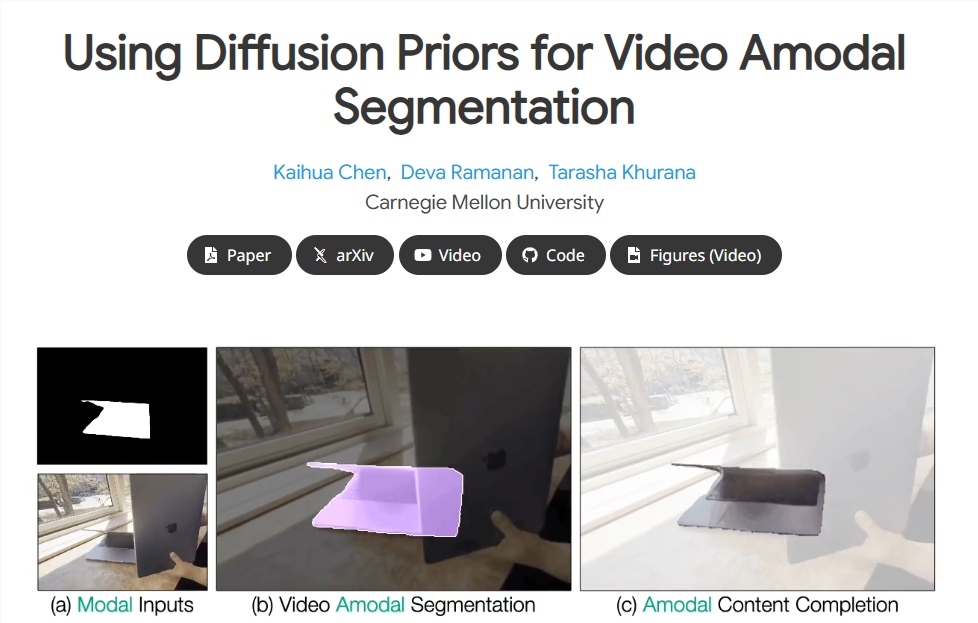
第二阶段:内容补全
在第一阶段创建非模态掩码之后,第二阶段则专注于补全被遮挡区域的内容。研究团队利用模态 RGB 内容并实施 条件生成模型 来填充这些被遮挡区域,最终生成完整的非模态 RGB 内容。整个过程在 条件潜在扩散框架 内执行,依托 3D UNet 背景,确保生成输出的高保真度。
验证与结果
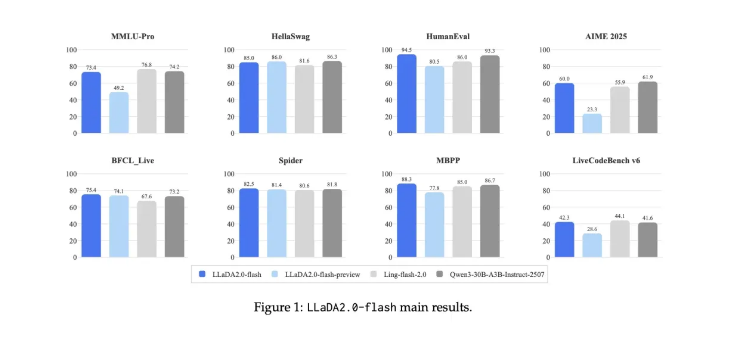
为了评估 Diffusion-Vas 方法的有效性,研究团队在四个不同的数据集上进行了基准测试。结果表明,在被遮挡区域的非模态分割准确性上有显著提高,与各种先进方法相比,提升幅度可达到 13%。值得注意的是,Diffusion-Vas 方法在复杂场景中表现出卓越的鲁棒性,有效应对强镜头运动和频繁的完全遮挡。
这项研究不仅提高了视频分析的准确性,还提供了在复杂环境中理解对象存在的新视角。这项技术的潜在应用非常广泛,未来预计将在 自动驾驶 和 监控视频分析 等领域实施。
有关该项目的更多详细信息,请访问 Diffusion-Vas Project.
关键点
- 该研究推出了一种使用扩散先验进行视频中非模态分割和内容补全的新方法。
- 该方法分为两个阶段:第一,生成非模态掩码;第二,完成被遮挡区域的内容。
- 基准测试表明,在复杂场景中,非模态分割的准确性显著提高。