vLLM-Omni:统一AI多模态的强大框架
多模态AI的统一解决方案
随着vLLM-Omni的发布,AI领域迎来重大突破。这个开源框架首次将文本、图像、音频和视频生成能力整合于一体。由vLLM团队开发的创新方案,将理论构想转化为开发者可立即落地的实用代码。
工作原理:组件拆解
vLLM-Omni的核心采用解耦式管道架构智能分配工作负载:
- 模态编码器(如ViT和Whisper)负责将视觉与语音输入转换为中间特征
- LLM核心沿用vLLM成熟的自动回归引擎进行推理对话
- 模态生成器利用扩散模型(包括DiT和Stable Diffusion)产生最终输出
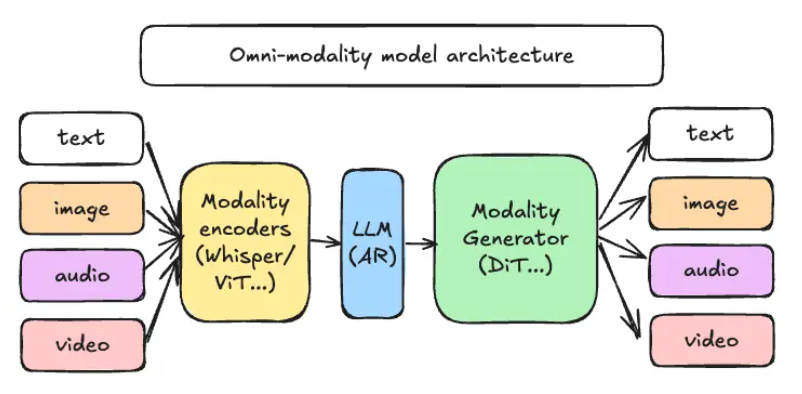
该方案的巧妙之处在于灵活性——每个组件作为独立微服务运行,可分布在不同GPU或节点上。需要增强图像生成能力?扩展DiT模块;遇到文本密集型任务?动态调整资源分配。据报告这种弹性扩展可使GPU内存利用率提升达40%。
令人瞩目的性能表现
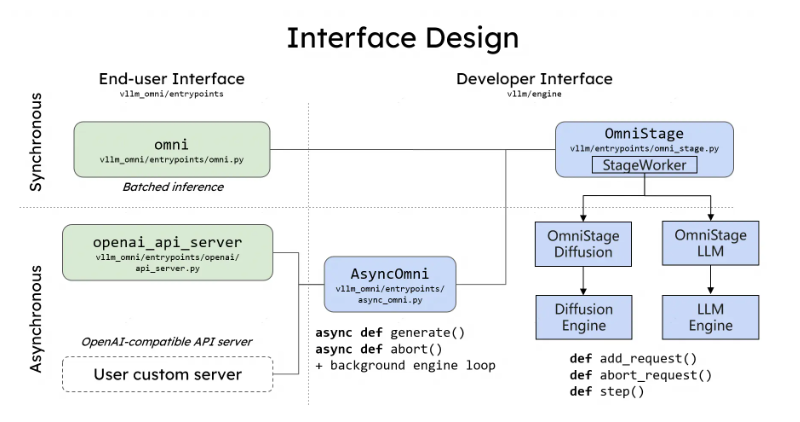
针对担心集成复杂度的开发者,vLLM-Omni提供了极简解决方案:@omni_pipeline Python装饰器。仅需三行代码,即可将单模态模型升级为多模态系统。
基准测试数据令人印象深刻:在运行100亿参数"文本+图像"模型的8×A100集群上:
- 吞吐量达到传统串行方案的2.1倍
- 端到端延迟降低35%
vLLM-Omni的未来规划
开发团队并未止步于此。当前GitHub版本已包含完整示例和Docker Compose脚本,支持PyTorch 2.4+与CUDA 12.2。展望2026年第一季度:
- 计划集成视频DiT模型
- 将新增语音编解码器支持
- Kubernetes CRD功能实现私有云一键部署
该项目有望大幅降低初创企业构建"文本-图像-视频"统一平台的门槛,无需维护独立推理管道。
行业反响与现存挑战
虽然专家们称赞该框架统一异构模型的创新方法,但对生产就绪度仍持审慎态度:
"不同硬件配置间的负载均衡与缓存一致性维护仍是实际挑战,"一位行业观察者指出。
作为通向多模态AI民主化的重要一步,这项先锋技术仍需时间沉淀成熟。 项目仓库
核心亮点:
- 首个整合文本/图像/音频/视频生成的"全模态"框架
- 解耦架构实现跨GPU弹性扩展
- Python装饰器(@omni_pipeline)简化集成流程
- 基准测试显示吞吐量提升2.1倍
- 2026年计划支持视频DiT与语音编解码器