蚂蚁集团LLaDA2.0:千亿参数突破AI语言模型新高度
蚂蚁集团开源LLaDA2.0实现技术突破
在震撼AI界的重大举措中,蚂蚁集团技术研究院发布了LLaDA2.0——业界首个千亿参数离散扩散语言模型(dLLM)。这不仅是渐进式更新,更代表着我们对扩散模型语言处理规模化认知的根本性转变。
LLaDA2.0的独特之处
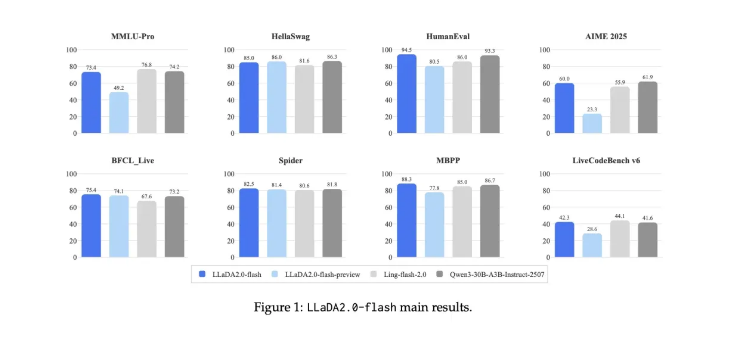
该模型提供两种版本:轻量级16B(mini)版和重量级100B(flash)版。大模型尤其在代码生成和指令执行等多数模型易出错的复杂挑战中表现突出。
"我们破解了扩散模型的规模化密码,"蚂蚁集团发言人解释道,"我们的Warmup-Stable-Decay(WSD)预训练策略让LLaDA2.0能够基于现有自回归模型知识构建,而非从零开始——既节省时间又节约资源。"
令人瞩目的速度表现
开发者将在此获得惊喜:
- 闪电般处理速度达每秒535个token
- 比同类自回归模型快2.1倍
- 通过创新的KV缓存复用和块级并行解码实现
团队并未止步于此。在后训练阶段,他们采用互补掩码和置信度感知并行训练(CAP)技术进一步优化性能。
卓越的实际表现
早期测试显示LLaDA2.0在关键领域表现出色:
- 具备优越结构规划的代码生成能力
- 需要细致理解的复杂代理调用
- 要求持续连贯性的长文本任务
该模型展现出惊人的适应性——从技术编程场景到创意写作练习的多样化应用中游刃有余。
对AI未来的意义
此次发布不仅引入了又一个大型语言模型,更从根本上改变了我们对大规模扩散模型能力的认知。蚂蚁集团开源LLaDA2.0的决定邀请全球协作,有望加速整个AI领域的创新进程。
公司已透露未来发展计划包括:
- 进一步扩展参数规模
- 整合强化学习技术
- 探索生成式AI的新思维范式
该模型现已在https://huggingface.co/collections/inclusionAI/llada-20开放探索。
关键亮点:
- 行业首创: 千亿参数离散扩散语言模型
- 速度王者: 每秒处理535个token(比竞品快2.1倍)
- 代码专家: 擅长复杂编程任务
- 开放邀请: 现已在Hugging Face面向全球开发者开放