VLM2Vec-V2: A Unified Framework for Multimodal Retrieval
Breakthrough in Multimodal Learning: VLM2Vec-V2 Bridges Visual Data Types
A collaborative research team from Salesforce Research, University of California, Santa Barbara, University of Waterloo, and Tsinghua University has unveiled VLM2Vec-V2, a revolutionary multimodal embedding learning framework designed to unify retrieval tasks across images, videos, and visual documents.
Addressing Current Limitations
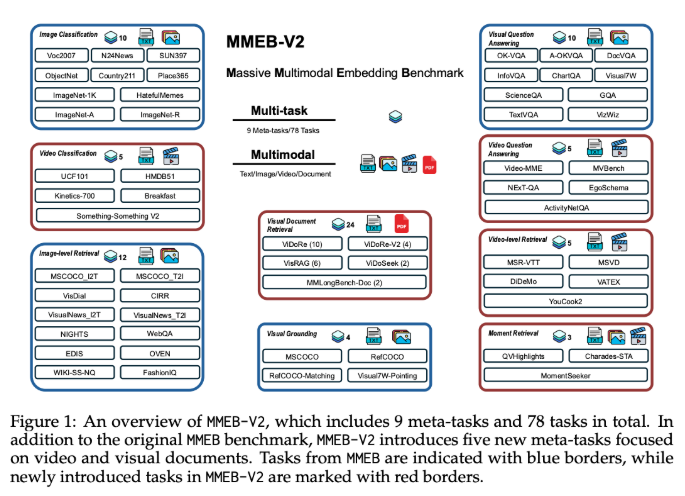
Existing multimodal embedding models have primarily focused on natural images from datasets like MSCOCO, Flickr, and ImageNet. These models struggle with broader visual information types including documents, PDFs, websites, videos, and slides - creating performance gaps in practical applications like article search and video retrieval.
Expanded Capabilities
The VLM2Vec-V2 framework introduces several key advancements:
- Expanded MMEB dataset with five new task types
- Support for visual document retrieval
- Enhanced video retrieval capabilities
- Temporal localization functionality
- Integrated video classification and question answering
Technical Innovations
The model builds on the Qwen2-VL architecture, incorporating:
- Simple dynamic resolution
- Multi-modal rotation position embedding (M-RoPE)
- Unified framework combining 2D/3D convolution
- Flexible data sampling pipeline for stable contrastive learning
Performance Benchmarks
In comprehensive testing across 78 datasets, VLM2Vec-V2 achieved:
- Highest average score of 58.0
- Superior performance in both image and video tasks
- Competitive results against specialized models like ColPali in document retrieval
The framework is now available on GitHub and Hugging Face.
Key Points:
- 🚀 Unified framework for images, videos, and documents
- 📊 Expanded evaluation dataset with diverse task types
- ⚡ Outperforms existing benchmarks in comprehensive testing
- 🔍 Open-source availability accelerates research adoption