Tencent Open-Sources AI Video Sound Model HunyuanVideo-Foley
Tencent's Breakthrough in AI-Generated Video Sound Effects
On August 28, 2025, Tencent Hunyuan made a significant advancement in multimedia AI by open-sourcing its HunyuanVideo-Foley model - an end-to-end solution for generating synchronized sound effects from video inputs. This development marks a pivotal moment in overcoming the "silent video" limitation of current AI-generated content.
Technical Innovation and Capabilities
The model introduces three groundbreaking solutions to longstanding audio generation challenges:
Enhanced Generalization: Through construction of a massive TV2A (Text-Video-Audio) dataset, the system adapts to diverse content including human actions, wildlife, natural environments, and animated scenes.
Dual-Stream Architecture: The proprietary Multimodal Diffusion Transformer (MMDiT) framework balances visual and textual semantics to produce complex, layered soundscapes that remain perfectly synchronized with on-screen action.
Audio Fidelity: Implementation of a Representation Alignment (REPA) loss function ensures professional-grade audio quality and temporal consistency.
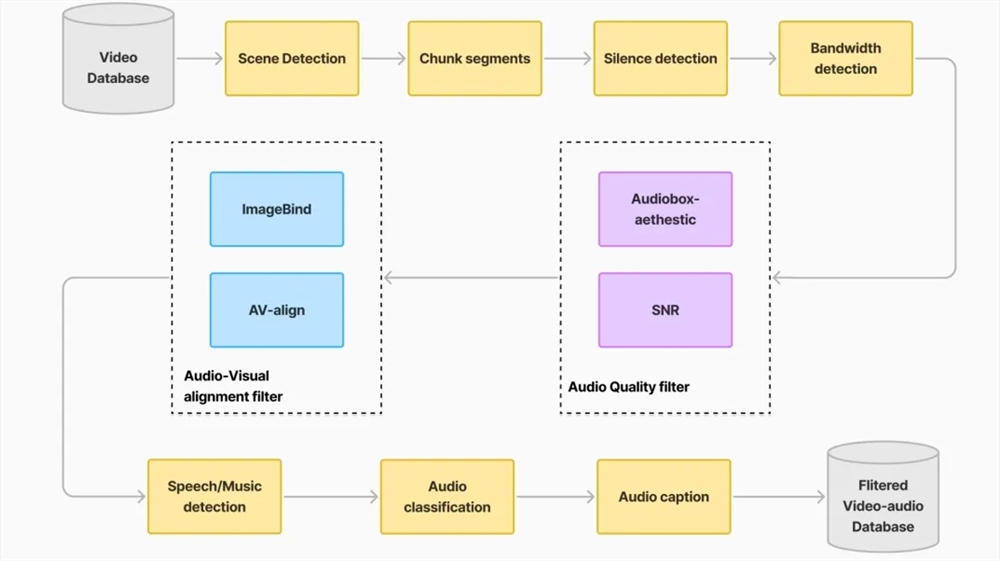
Performance Benchmarks
Independent evaluations demonstrate HunyuanVideo-Foley's industry-leading capabilities:
- Audio Quality (PQ): Improved from 6.17 to 6.59
- Visual Alignment (IB): Increased from 0.27 to 0.35
- Temporal Sync (DeSync): Enhanced from 0.80 to 0.74
In subjective testing across three dimensions (audio quality, semantic matching, and timing), the model achieved average scores exceeding 4.1/5 points - approaching professional production standards.
Practical Applications
The open-source release enables:
- Content Creators: Instant contextual sound generation for short videos
- Film Production: Rapid ambient sound design prototyping
- Game Development: Efficient creation of immersive audio environments
Availability
The model is now accessible through multiple platforms:
Key Points:
- First end-to-end open-source solution for video sound effect generation
- Outperforms previous methods in all benchmark categories
- Democratizes professional-grade audio production for various media applications
- Available immediately for commercial and research use