Tencent and Tsinghua's AI Music Breakthrough Challenges Industry Leaders
Tencent and Tsinghua University Unveil Game-Changing AI Music Model
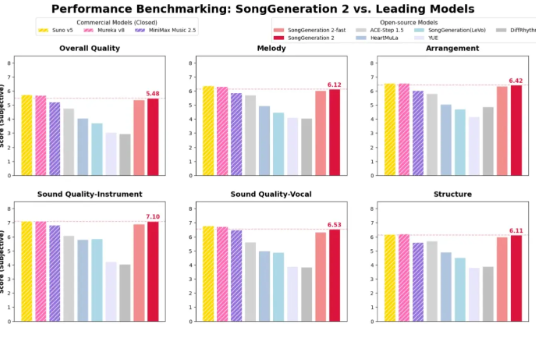
The AI music landscape just got more interesting. Tencent, in collaboration with Tsinghua University's Human-Computer Speech Interaction Lab, has launched SongGeneration2 - a foundation model that's setting new benchmarks in artificial music creation.
Solving AI Music's Biggest Problems
What makes SongGeneration2 stand out? It tackles three persistent issues that have plagued earlier AI music systems:
- Musical sophistication: Gone are the days of simplistic melodies. This model handles complex multi-track arrangements with professional-level spatial depth.
- Crystal-clear vocals: Pronunciation errors and pitch fluctuations? Significantly reduced. With a phoneme error rate of just 8.55%, it outperforms Suno v5 (12.4%) and comes close to MiniMax2.5.
- Precision control: Whether you're describing your vision in text or providing audio examples, the model follows instructions remarkably well for customized style and emotion.
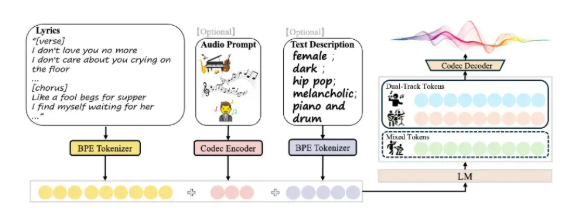
How It Works: The Tech Behind the Magic
The secret sauce lies in SongGeneration2's hybrid architecture:
- LeLM (Composing Brain): Acts as the musical director, planning overall structure and vocal details.
- Diffusion Renderer: Handles the intricate acoustic details under LeLM's guidance.
- Parallel Processing: Innovatively models both mixed representations and multi-track elements simultaneously.
Democratizing Music Creation
In a move that'll excite developers everywhere, Tencent has open-sourced the 4B parameter version (SongGeneration-v2-large). Even more impressive? It runs smoothly on consumer hardware with just 22GB VRAM - putting professional-grade music creation within reach of home users.
For those who want instant results, there's SongGeneration-v2-Fast on HuggingFace - generating complete songs in under a minute with only minor quality trade-offs.
As these tools become more accessible, we're witnessing AI music transition from tech demo to practical tool - potentially transforming how we all create and experience music.
Key Points:
- New hybrid LLM-diffusion architecture sets performance benchmarks
- Phonetic accuracy surpasses many commercial competitors (8.55% PER)
- Open-source approach lowers barriers to entry for creators
- Runs efficiently on consumer-grade hardware (22GB VRAM)
- Fast version generates complete songs in under one minute