NVIDIA's Compact AI Model Outperforms GPT-5 Pro at Fraction of Cost
NVIDIA's Small but Mighty AI Model Beats the Giants
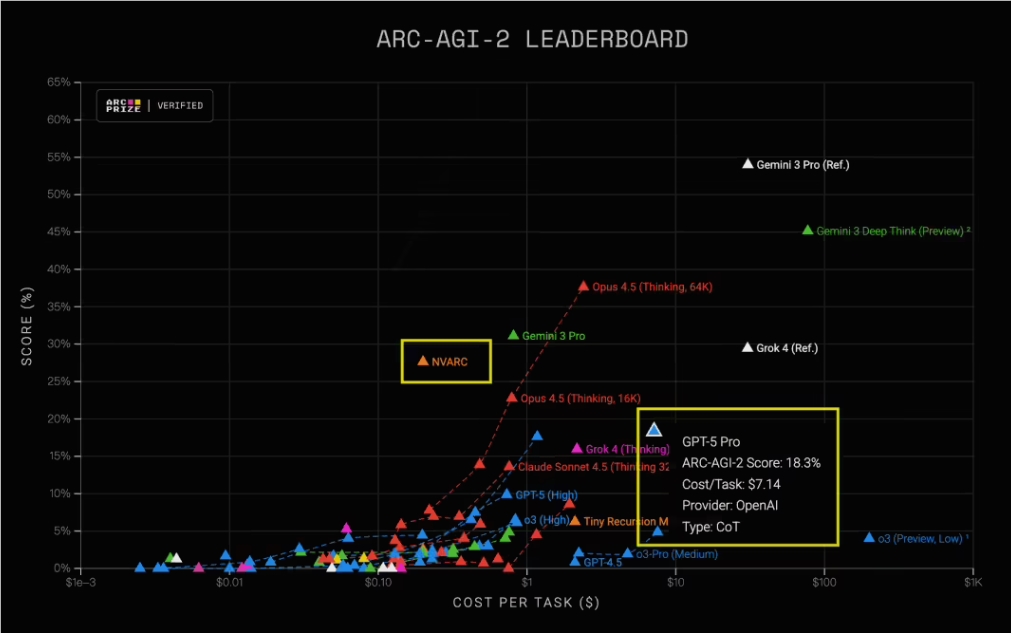
In an unexpected twist in artificial intelligence development, NVIDIA's compact NVARC model has outpaced heavyweight competitors like GPT-5 Pro in rigorous AGI testing. Scoring an impressive 27.64% on the demanding ARC-AGI2 evaluation - nearly 10 percentage points higher than GPT-5 Pro's 18.3% - this lightweight contender proves size isn't everything.
The Cost Efficiency Champion
What makes NVARC truly remarkable isn't just its performance, but its staggering cost advantage. While GPT-5 Pro burns through $7 per task, NVARC completes the same work for mere pennies - just 20 cents. That's a jaw-dropping 97% reduction in operational costs.
"We're seeing diminishing returns from simply scaling up models," explains Dr. Lisa Chen, an AI researcher unaffiliated with the project. "NVARC shows how innovative training approaches can outperform models hundreds of times larger."
Breaking Free from Data Dependence
The secret sauce? NVIDIA completely skipped traditional pretraining on massive datasets - a radical departure from current industry norms. Instead, they developed a zero-pretraining deep learning approach that avoids the domain bias and data dependency plaguing larger models.
The ARC-AGI2 tests were specifically designed to push boundaries, evaluating whether models could learn new skills without direct training data - exactly where NVARC excelled.
Synthetic Puzzles Power Smarter Learning
The NVIDIA team took an ingenious shortcut: they moved complex reasoning processes offline using GPT-OSS-120B to generate high-quality synthetic puzzles. This created a treasure trove of training material without requiring real-time computing resources.
Here's how they did it:
- Started with questions from existing datasets
- Combined them creatively to form more complex challenges
- Broke down reasoning into verifiable steps
- Built a massive synthetic dataset of 3.2 million enhanced samples
The result? A model that learns faster while consuming far fewer resources.
Technical Innovations Behind the Breakthrough
NVARC incorporates several clever technical advances:
- ARChitects method: Improved reasoning module architecture
- Conversational templates: Simplified puzzle understanding
- NeMo RL framework: For supervised fine-tuning
- TTFT technology: Task-specific fine-tuning for rapid adaptation
The implications are profound: we might be entering an era where optimized small models outperform their bloated counterparts for many practical applications.
Why Smaller Might Be Smarter
The success of NVARC challenges conventional wisdom about AI scaling:
- Cost: Dramatically cheaper to run
- Speed: Faster response times
- Adaptability: Quicker to specialize for new tasks
- Sustainability: Lower energy consumption
"This isn't about replacing large models," Chen notes, "but finding the right tool for each job."
As organizations grapple with skyrocketing AI costs, NVARC offers a compelling alternative where extreme scale isn't necessary.
# Key Points:
- NVIDIA's compact NVARC model (4B parameters) outperformed GPT-5 Pro in AGI testing (27.64% vs 18.3%) Costs just $0.20 per task vs GPT-5 Pro's $7 Uses innovative zero-pretraining approach Leverages synthetic data generation offline Demonstrates small models can excel at specific tasks * Could reshape cost-benefit calculations for enterprise AI





