Moonshot's Kimi Linear Model Boosts AI Processing Speed
Moonshot's Kimi Linear Model Revolutionizes AI Processing
In a significant leap for Artificial Intelligence Generated Content (AIGC), Moonshot has unveiled its Kimi Linear model, delivering unprecedented efficiency gains. The model processes long contexts 2.9 times faster and decodes information 6 times quicker than conventional systems, addressing critical bottlenecks in AI performance.
Breaking Traditional Limitations
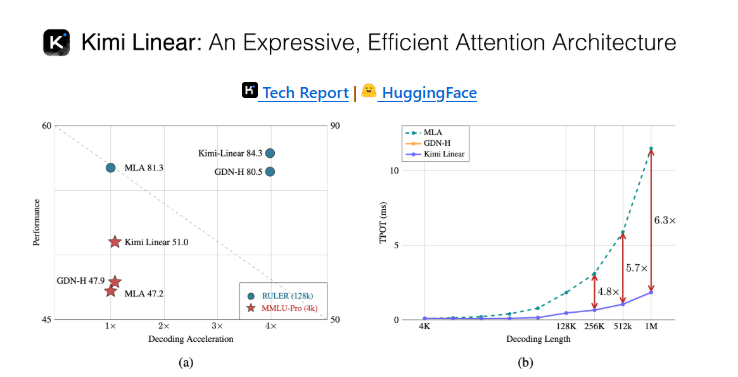
Traditional Transformer models rely on the Softmax attention mechanism, which suffers from an O(n²) computational complexity. This exponential growth in resource demands severely limits practical applications, especially with lengthy texts. Kimi Linear's breakthrough lies in its linear attention approach, reducing complexity to O(n) while maintaining high accuracy.
Innovative Architecture: KDA and Moonlight
The model's core innovation is the Kimi Delta Attention (KDA) mechanism, which introduces a fine-grained gating system to dynamically manage memory states. KDA optimizes information retention and forgetting, crucial for prolonged interactions.
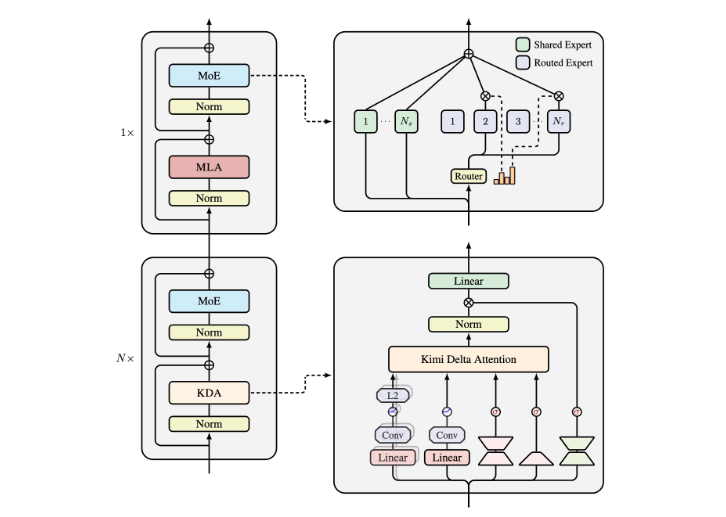
Complementing KDA is the Moonlight architecture, blending KDA with full-attention layers in a 3:1 ratio. This hybrid design balances computational efficiency with robust model capabilities, excelling in tasks requiring extensive context memory.
Proven Performance Advantages
Experimental results highlight Kimi Linear's superiority:
- Palindrome tasks: Enhanced accuracy through precise long-context handling.
- Multi-query correlation recall: Superior performance in complex retrieval scenarios.
The model's efficiency opens new possibilities for real-time AIGC applications, from automated content generation to advanced reinforcement learning systems.
Key Points:
- 🚀 2.9x faster long-context processing and 6x quicker decoding speeds.
- 🔧 Kimi Delta Attention (KDA) refines memory management via dynamic gating.
- ⚖️ 3:1 hybrid architecture ensures optimal balance between speed and accuracy.