MiniMax Unveils M2.1 Model with Developer-Friendly Pricing
MiniMax's M2.1 Model: A Developer's New Best Friend
The AI development community just got an early holiday present. MiniMax has thrown open the doors to its M2.1 programming model, making it freely available on Hugging Face, ModelScope, and GitHub. This isn't just another model release - it's packed with features that developers have been craving.
Performance Meets Accessibility
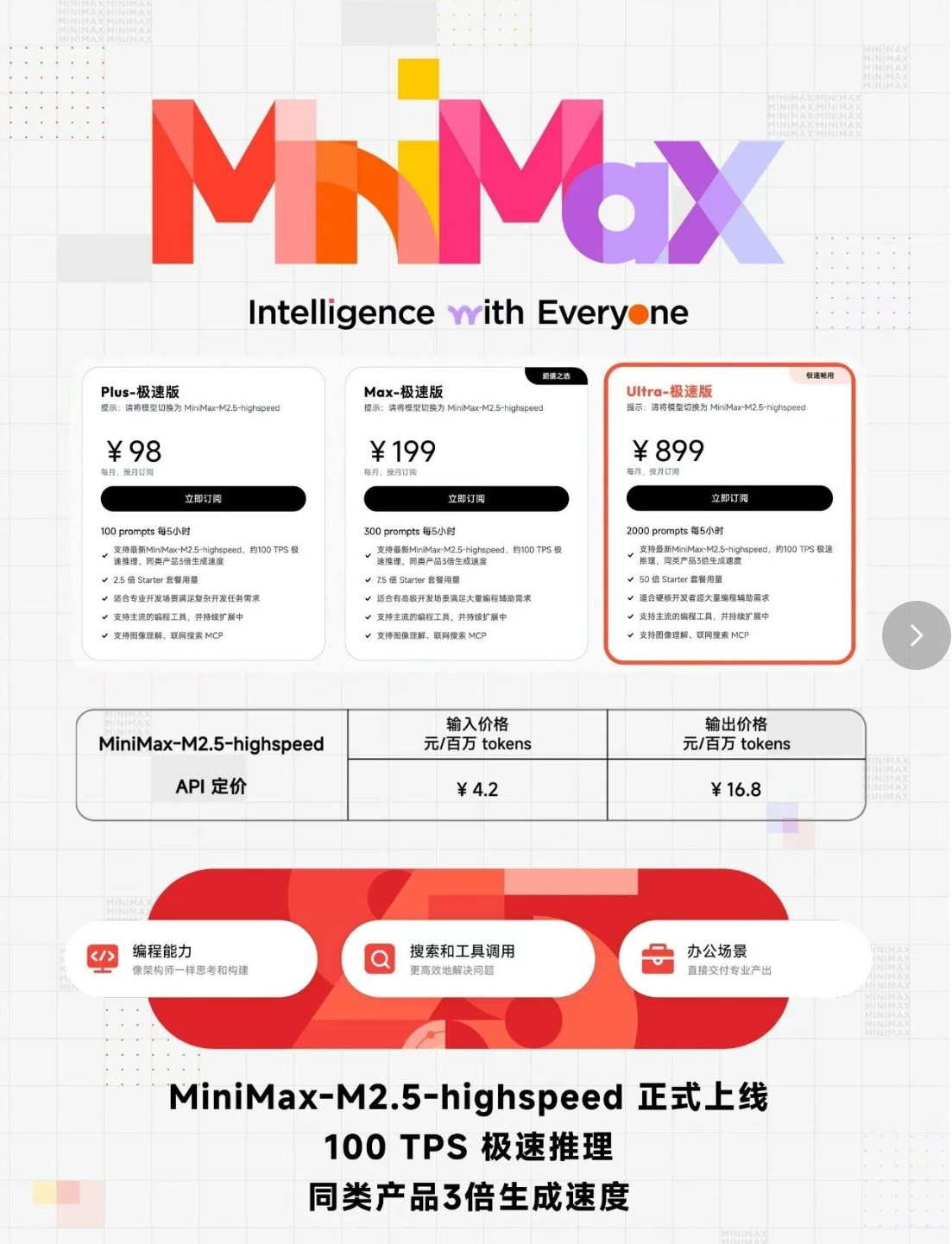
What sets M2.1 apart? For starters, it arrives with "Day-0" vLLM support - meaning developers can hit the ground running with optimized inference performance from minute one. The real game-changer comes with KTransformers technology, enabling smooth FP8 local inference on powerhouse devices like NVIDIA's RTX5090.
"We wanted to eliminate the usual waiting period," explains a MiniMax spokesperson. "When developers are excited about new tech, they shouldn't have to wait weeks for compatibility updates."
Budget-Conscious Innovation
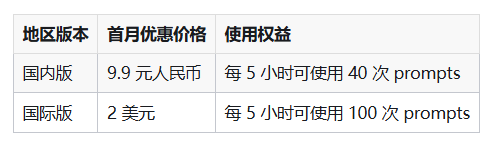
MiniMax isn't just thinking about performance - they're considering developers' wallets too. Their "Starter Plan" turns heads at just 9.9 RMB monthly (or $2 internationally), offering:
- Domestic users: 40 prompts every 5 hours
- International users: 100 prompts every 5 hours
The promotion runs through January 15, 2026, giving ample time for curious developers to test-drive the model.
Double the Savings
The savings don't stop there. Through February 28, 2026, MiniMax's referral program offers:
- 10% discount on subscriptions/upgrades for both referrer and referee
- Stackable savings when combined with Starter Plan discounts
The message is clear: MiniMax wants to remove financial barriers holding back AI innovation.
Why This Matters Now
The timing couldn't be better as industries increasingly lean on AI solutions:
- Research teams gain powerful new tools without budget strain
- Startups can prototype faster with accessible pricing tiers
- Educators now have affordable options for student projects
The M2.1 model represents more than technical advancement - it's democratizing access to cutting-edge AI development.
Key Points:
- Instant Compatibility: Day-0 vLLM support eliminates typical adoption delays
- Local Power: KTransformers enables efficient FP8 inference on high-end GPUs
- Budget-Friendly: Starter Plans begin at just $2/9.9 RMB monthly
- Extended Savings: Referral program offers stackable discounts through February