Meta's Matrix Framework Breaks Bottlenecks in AI Data Generation
Meta's New Approach to Synthetic Data Challenges
Anyone who's worked with large language models knows the struggle: generating enough diverse, high-quality synthetic data without creating bottlenecks. Meta AI researchers believe they've cracked this problem with their new Matrix framework, which fundamentally rethinks how synthetic dialogues and reasoning chains get produced.
Why Current Systems Fall Short
Traditional approaches rely on centralized controllers that manage all agent interactions—a bit like having one overwhelmed air traffic controller trying to coordinate thousands of planes simultaneously. While conceptually simple, this architecture hits serious limits when scaling up.
"When you're generating millions of synthetic conversations," explains lead researcher Amanda Chen, "that single point of coordination becomes a major bottleneck. Agents sit idle waiting their turn while GPUs go underutilized."
How Matrix Changes the Game
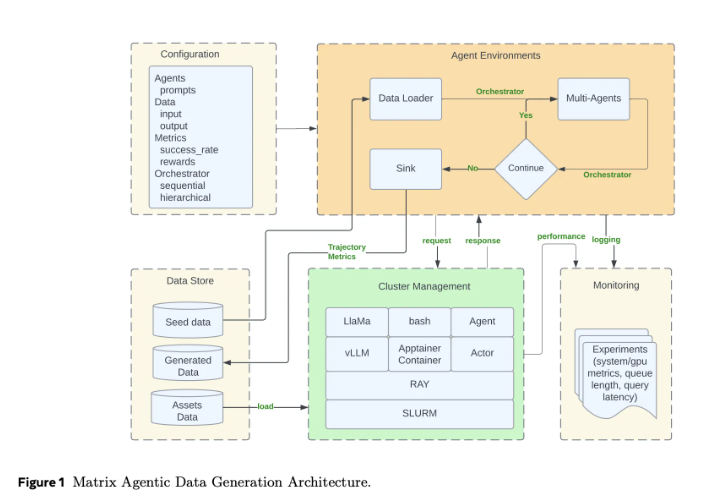
The breakthrough comes from Matrix's decentralized design:
- Instead of a central controller, agents communicate peer-to-peer through messages
- Each specialized agent (dialogue generator, fact checker, etc.) operates independently
- Workflows get serialized into "scheduler" message objects passed between agents
- Ray cluster technology handles the distributed computing heavy lifting
The results speak for themselves: in testing, Matrix generated 200 million tokens where traditional methods managed just 62 million—all while maintaining equivalent quality standards.
Real-World Performance Gains
The team demonstrated Matrix's advantages across three key scenarios:
- Dialogue generation: 3.2x more tokens produced for Collaborative Reasoner training
- Dataset creation: 2.1x throughput boost building the NaturalReasoning dataset
- Tool usage trajectories: Stunning 15.4x improvement in Tau2-Bench evaluations
The secret sauce? Matrix eliminates coordination overhead while optimizing resource use through clever techniques like message offloading—storing large conversation histories separately to reduce network strain.
What This Means for AI Development
As synthetic data becomes increasingly crucial for training advanced models, solutions like Matrix could dramatically accelerate progress across the field. The framework isn't just faster—its decentralized nature makes it more resilient too, with failures affecting only small parts of ongoing operations rather than bringing down entire workflows.
The team has open-sourced their work via arXiv (paper link), inviting the broader AI community to build upon their innovations.
Key Points:
- Decentralized design avoids single-point bottlenecks plaguing current systems
- Peer-to-peer messaging enables agents to work independently yet coordinatedly
- 2-15x speed improvements demonstrated across multiple use cases
- Ray cluster integration provides robust distributed computing foundation