Meta's DreamGym Gives AI Agents a Virtual Training Ground
Meta's New Virtual Gym Trains Smarter AI Agents
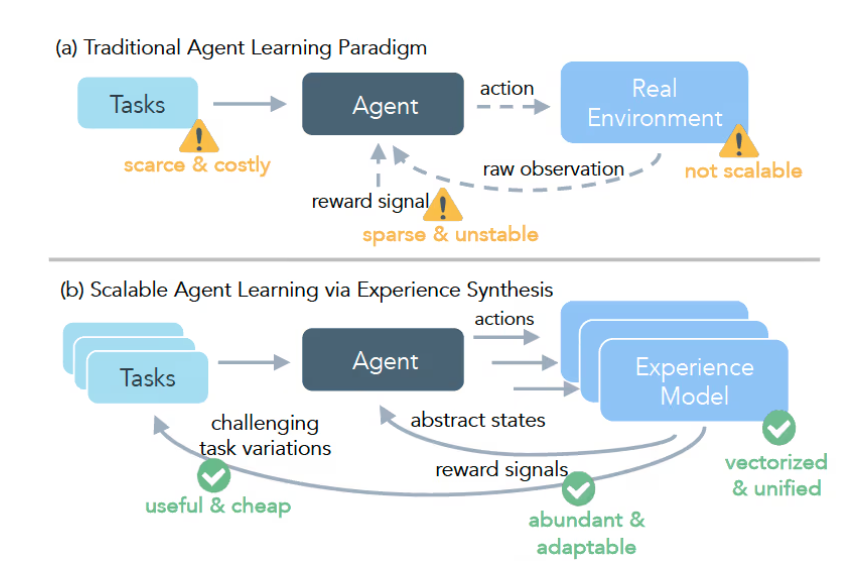
Imagine trying to teach someone basketball by only letting them play in championship games. That's essentially how we've been training many AI systems - throwing them into complex real-world scenarios with little preparation. Meta aims to change this with DreamGym, a groundbreaking framework developed alongside researchers from the University of Chicago and UC Berkeley.
Why Traditional Training Falls Short
Training large language model agents through reinforcement learning faces significant hurdles:
- Costly mistakes: Real-world training often requires expensive hardware and creates risks
- Sparse feedback: Like getting only one grade at semester's end instead of regular quizzes
- Expert dependence: Human oversight drives up costs and slows progress
DreamGym tackles these challenges head-on by creating sophisticated virtual training environments where AI can safely learn from mistakes.
How DreamGym Works Its Magic
The framework operates like a personal trainer for AI agents:
- Virtual playground: The "reasoning-based experience model" converts real environments into text simulations
- Memory bank: An "experience replay buffer" stores lessons learned to guide future decisions
- Adaptive challenges: The "curriculum task generator" constantly adjusts difficulty based on performance
Together, these components create a virtuous cycle of learning where agents progressively tackle harder problems.
Real-World Results That Impress
The research team put DreamGym through rigorous testing across multiple domains:
- E-commerce platforms
- Sensory control systems
- Actual web interactions
The standout success came in WebArena environments, where DreamGym-trained agents achieved success rates more than 30% higher than conventional methods. Perhaps most remarkably, the system matched the performance of popular algorithms while relying solely on synthetic interactions - potentially saving millions in data collection costs.
Key Points:
- 🏋️♂️ Virtual training ground: DreamGym creates safe simulations for AI learning
- 📈 Adaptive difficulty: Tasks automatically scale to challenge growing skills
- 💰 Cost effective: Reduces need for expensive real-world trials
- 🏆 Proven results: Outperforms traditional methods across multiple benchmarks