Meituan's New AI Model Packs a Punch with Smart Parameter Tricks
Meituan Rewrites the Rules for Efficient AI Models

In the world of AI, bigger hasn't always meant better. While most teams keep stacking more 'experts' into their models, Meituan's LongCat crew took a different path. Their newly launched LongCat-Flash-Lite proves that smarter parameter use can outperform brute-force scaling.
The Embedding Layer Breakthrough
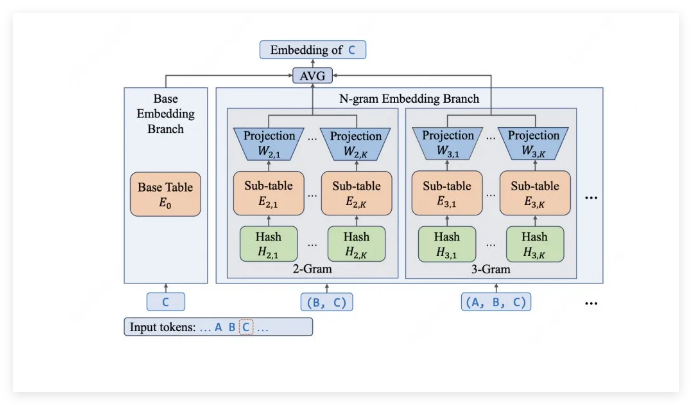
Traditional MoE (Mixture of Experts) architectures hit diminishing returns as they grow. But here's where Meituan's approach stands out: by strategically beefing up the embedding layer rather than just adding experts, they've created a model that activates only 2.9 to 4.5 billion parameters per task - despite packing 68.5 billion total parameters.
The secret sauce? An N-gram embedding system that captures local patterns with surgical precision. Need to understand programming commands or technical jargon? The model spots these patterns like a seasoned coder recognizing familiar syntax.
Engineering Magic Behind the Scenes
Turning theoretical advantages into real-world speed required three clever optimizations:
- Smart Parameter Budgeting: Nearly half the model's capacity lives in its embedding layer, using efficient O(1) lookups instead of costly computations.
- Custom Hardware Tricks: The team built specialized caching (think of it as a supercharged N-gram memory) and fused key operations together to slash processing delays.
- Prediction Teamwork: By combining speculative decoding with their unique architecture, they achieve blistering speeds of 500-700 tokens per second while handling massive 256K context windows.
Performance That Turns Heads
The numbers tell an impressive story:
- Coding Prowess: Scored 54.4% on SWE-Bench and dominated terminal command tests (33.75 on TerminalBench)
- Agent Excellence: Topped industry-specific benchmarks for telecom, retail and aviation scenarios
- General Smarts: Matches Gemini2.5Flash-Lite on MMLU (85.52) while holding its own in advanced math
The best part? Meituan is putting everything out there - model weights, technical deep dives, even their custom inference engine (SGLang-FluentLLM). Developers can grab 50 million free tokens daily through the LongCat API platform to test drive this innovative approach.
Key Points:
- Breaks from traditional MoE scaling by optimizing embedding layers instead of just adding experts
- Achieves large-model performance while activating only 4.5B parameters per task
- Specialized caching and kernel fusion deliver exceptional speed (500+ tokens/sec)
- Open-source release includes weights, technical reports and inference engine