Llamafile 0.9.3 Adds Qwen3 Support for Simplified AI Deployment
The open-source Llamafile project under Mozilla has unveiled version 0.9.3, bringing significant advancements in large language model accessibility. This update introduces support for Alibaba Cloud's Qwen3 series, marking a major step forward in simplified AI deployment.
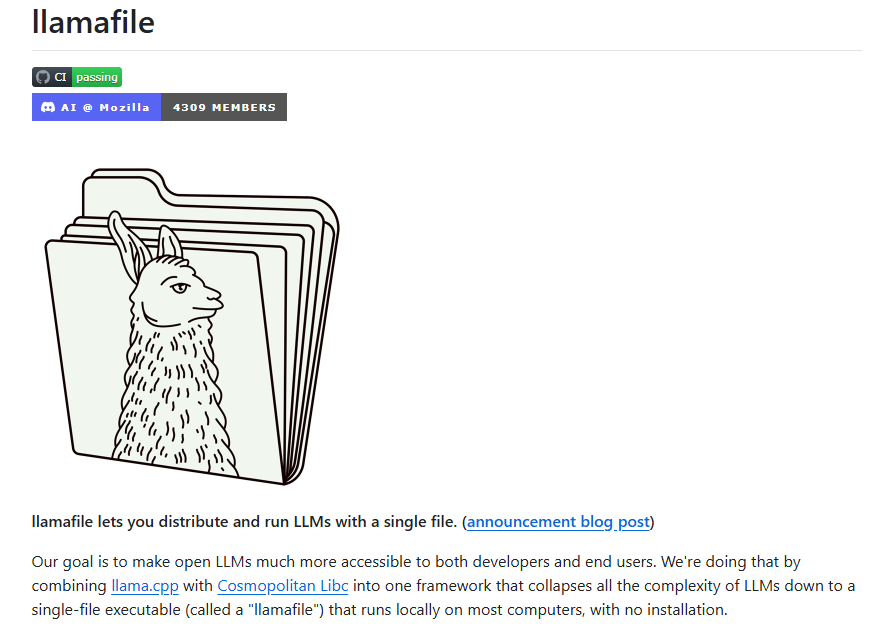
Single-File Revolution Llamafile's breakthrough lies in its single-executable design, combining llama.cpp's inference capabilities with Cosmopolitan Libc's cross-platform functionality. This innovative approach packages model weights, inference code, and runtime environment into one file that runs on Windows, macOS, Linux, FreeBSD, OpenBSD, and NetBSD without complex installations.
The new version supports multiple Qwen3 models including the 30-billion-parameter Qwen3-30B-A3B, along with smaller variants like Qwen3-4B and Qwen3-0.6B. Stored in GGUF format with quantization optimization, these models can run efficiently on consumer hardware - the Qwen3-30B-A3B operates smoothly on devices with just 16GB RAM.
Enhanced Performance Qwen3 brings notable improvements in coding, mathematics, and multilingual processing (supporting 119 languages). The integration allows mixed CPU/GPU inference through llama.cpp updates (version b5092+), supporting 2 to 8-bit quantization that dramatically reduces memory needs. Benchmarks show the quantized Qwen3-4B generating over 20 tokens per second on standard laptops.
Universal Compatibility Cosmopolitan Libc enables true cross-platform operation through dynamic runtime scheduling that adapts to various CPU architectures (x86_64 and ARM64) and modern instruction sets (AVX, AVX2, Neon). Developers compile once in Linux for universal compatibility - tests confirm even Raspberry Pi devices can run smaller Qwen3 models at practical speeds.
The package includes a Web GUI chat interface and OpenAI-compatible API endpoints. Users launch local servers with simple commands like ./llamafile -m Qwen3-4B-Q8_0.gguf --host 0.0.0.0, accessing chat functionality via browser at localhost:8080.
Ecosystem Growth Beyond Qwen3 support, version 0.9.3 adds Phi4 model compatibility and improves the LocalScore benchmarking tool by 15%. The update incorporates llama.cpp's latest optimizations including enhanced matrix multiplication kernels and support for new architectures.
Available under Apache2.0 license, Llamafile encourages community development. Models are downloadable from Hugging Face (the Qwen3-30B-A3B comes as a single 4.2GB file), with customization possible through zipalign tools or integration with platforms like Ollama and LM Studio.
Industry Implications This release significantly lowers barriers to local AI implementation for individual developers, SMEs, and educational institutions while addressing privacy concerns inherent in cloud solutions. The technology shows particular promise for education, healthcare, and IoT applications where offline operation is essential.
While currently optimized for mid-sized models (up to ~30B parameters), future developments may address challenges with larger architectures like Qwen3-235B regarding file size management and memory optimization.
Project address: https://github.com/Mozilla-Ocho/llamafile
Key Points
- Single-file deployment eliminates complex setup across six operating systems
- Supports multiple Qwen3 variants including the powerful 30B parameter model
- Achieves practical performance on consumer hardware through quantization
- Enables true compile-once-run-anywhere functionality via Cosmopolitan Libc
- Includes user-friendly interfaces (Web GUI and OpenAI-compatible API)