Kuaishou Open-Sources KAT-V1 AI Model with Advanced Reasoning
Kuaishou Open-Sources Advanced KAT-V1 AI Model with Autonomous Thinking Capabilities
Chinese tech giant Kuaishou has officially released and open-sourced its KAT-V1 AutoThink large language model, marking a significant advancement in AI reasoning capabilities. The model demonstrates exceptional performance in balancing thinking and non-thinking operations, automatically adjusting its cognitive approach based on question complexity.
Model Architecture and Performance
The KAT-V1 comes in two versions:
- 40B parameter model: Shows performance comparable to DeepSeek-R1 (685B parameters) in auto-think mode
- 200B parameter model: Outperforms flagship models from Qwen, DeepSeek, and Llama series in multiple benchmarks
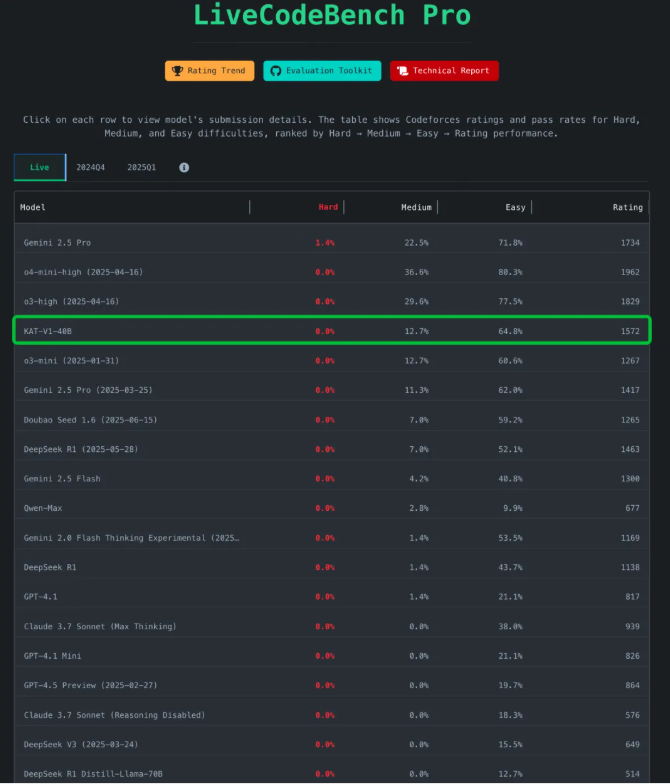
In the LiveCodeBench Pro real-time benchmark, the 40B version entered the closed-source model performance tier, surpassing many existing open-source alternatives. The Kwaipilot team at Kuaishou detailed several technological breakthroughs in their technical report, including:
- Hybrid training paradigm for short and long thinking processes
- Novel Step-SRPO reinforcement learning algorithm that enhances reasoning ability and thinking density
Solving the 'Overthinking' Problem
The development addresses a growing issue in AI systems since OpenAI's models popularized chain-of-thought reasoning. "Overthinking" leads to unnecessarily long response times and degraded user experience.
KAT-V1's optimization allows it to:
- Autonomously determine when deep thinking is necessary
- Maintain efficient human-computer collaboration
- Build upon June's KwaiCoder-AutoThink-preview solution with enhanced reasoning capabilities
Technical Innovations
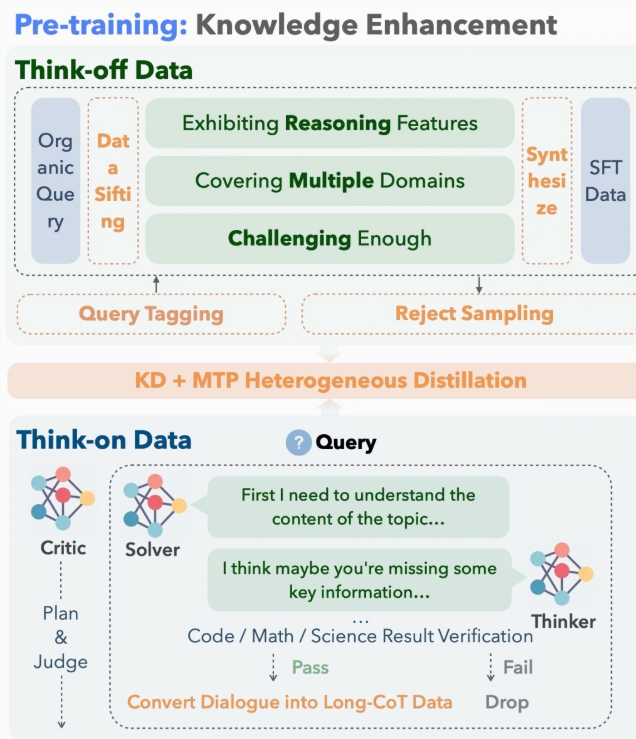
The model extends Qwen2.5-32B architecture with several key advancements:
Data Processing:
- Constructed extensive datasets of thinking/non-thinking examples
- Used ~10 million pre-training examples for multi-domain capability generalization (science, coding, mathematics)
Model Distillation:
- Implemented unique heterogeneous distillation framework
- Efficient knowledge transfer from teacher to student models
- Significant reduction in initialization costs
The post-training phase employed reinforcement learning to enhance intelligent decision-making. This enables KAT-V1 to:
- Select optimal thinking modes dynamically
- Achieve 95%+ of DeepSeek-R1-0528 performance on complex problems
The 40B version is currently available on Hugging Face, while the 200B MoE version remains under development with anticipated stronger capabilities.
Key Points:
- Kuaishou open-sources advanced reasoning model with autonomous thinking adjustment
- Two versions available: competitive 40B and superior-performing 200B parameter models
- Addresses industry-wide 'overthinking' problem in AI systems
- Features hybrid training paradigm and novel Step-SRPO algorithm
- Available now on Hugging Face platform