GPT-4o Unveils Singing Feature in Major Voice Mode Upgrade
OpenAI has significantly upgraded GPT-4o's voice capabilities, introducing a singing function that pushes the boundaries of AI interaction. The advanced voice mode now processes audio directly rather than converting speech to text first, cutting response times to just 320 milliseconds - faster than human reaction speeds.
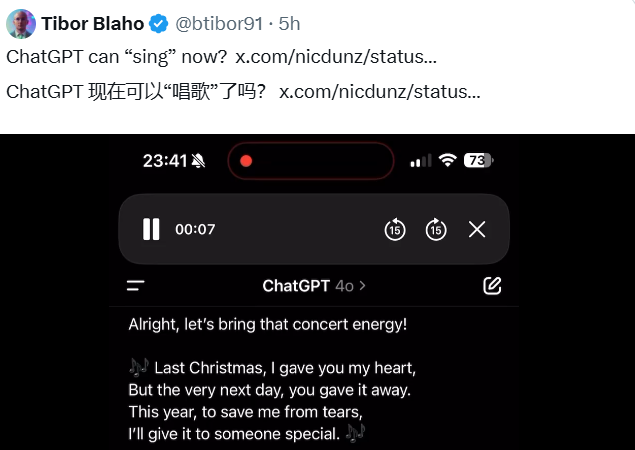
Singing Breakthrough with Room for Improvement Users can now ask GPT-4o to sing songs through voice commands, including some copyrighted material. The AI generates melodies and lyrics on demand, though early tests reveal limitations with complex musical passages. "The performance isn't quite concert-ready," admits one tester, noting occasional stiffness in high notes.
Emotional Intelligence Upgrade Beyond singing, GPT-4o demonstrates remarkable emotional range. It can laugh, cry, and adopt specific character voices - imagine requesting a Shakespearean monologue or your favorite cartoon character's tone. This emotional flexibility opens doors for education and entertainment applications.
Technical Advancements The system's end-to-end audio processing represents a major technical leap. Traditional voice assistants like Siri use separate components for speech recognition and generation, creating noticeable delays. GPT-4o's unified approach enables more natural conversations where users can interrupt freely.
Copyright Challenges Emerge OpenAI has implemented safeguards against copyright infringement, but some users report successfully prompting copyrighted song performances. This gray area raises questions about AI's role in creative content generation and intellectual property protection.
Future Potential While the singing feature needs polish, its introduction signals OpenAI's commitment to multimodal AI development. The technology could revolutionize language learning through interactive singing exercises or create personalized audiobook narration with emotional depth.
Key Points
- GPT-4o's new singing function expands AI creative capabilities despite current quality limitations
- Direct audio processing reduces response times to 320ms for fluid conversations
- Advanced emotional expression enables laughter, crying and character voices
- Copyright concerns emerge as users bypass some content restrictions
- Technology shows promise for education and entertainment applications