Google DeepMind's New Training Tech Keeps AI Learning Even When Hardware Fails
Google DeepMind's Breakthrough in Fault-Tolerant AI Training
Imagine an orchestra where if one musician faints, the whole concert stops. That's essentially how most AI training works today - until now. Google DeepMind's new Decoupled DiLoCo architecture changes the game by creating what engineers call "computing islands" that can operate independently.
The Problem With Current Systems
Traditional AI training methods require perfect synchronization between all hardware components. Every processor must wait for every other processor to finish calculations before moving forward - a digital version of "hurry up and wait." When even one chip fails (and in massive systems with thousands of components, failures happen constantly), everything grinds to a halt.
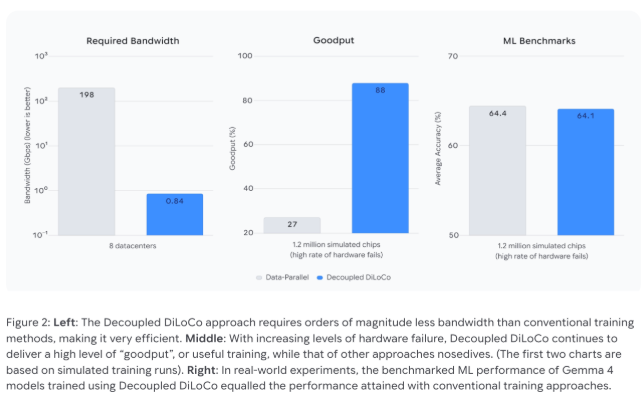
How DiLoCo Changes the Game
The system organizes processors into self-contained clusters called "learning units" that operate like miniature training centers. Each can complete multiple rounds of calculations before sending summarized updates to a central coordinator. This asynchronous approach means:
- No more domino effects when hardware fails
- Dramatically reduced bandwidth needs (from 198 Gbps to less than 1 Gbps)
- Older and newer chips can work together, extending equipment lifespans
"It's like switching from a relay race to parallel parking," explains one engineer familiar with the project. "Each car finds its own spot without blocking others."
Real-World Performance
The numbers speak volumes:
| Metric | Traditional Method | DiLoCo | Improvement |
|---|
The system even demonstrated remarkable resilience during chaos engineering tests - continuing to function when all learning units temporarily failed and smoothly reintegrating them upon recovery.
Why This Matters Beyond Tech Circles
This breakthrough could have ripple effects across industries:
- Environmental impact: Extending hardware life reduces e-waste
- Global collaboration: Makes distributed training feasible across continents
- Cost savings: Less downtime means faster model development cycles
As AI models grow increasingly massive (some now require months of continuous training), solutions like DiLoCo may become essential infrastructure rather than nice-to-have upgrades.
Key Points:
- 🛡️ Fault-tolerant design keeps training alive through hardware failures
- 🌐 Bandwidth efficiency enables practical global collaboration
- ♻️ Hardware flexibility allows mixing old and new equipment
- ⚡ Self-healing capability automatically recovers from disruptions

