Google DeepMind's New AI Training Tech Handles Hardware Glitches with Ease
Google DeepMind's Fault-Tolerant AI Training Breakthrough
In the high-stakes world of artificial intelligence development, hardware failures can bring multimillion-dollar training projects to a grinding halt. Google DeepMind's latest innovation aims to change that with a clever distributed training architecture called Decoupled DiLoCo.
The Problem with Traditional Methods
Current AI training approaches require all computing units to work in perfect sync - like an orchestra where every musician must play each note simultaneously. When one instrument falls out of tune (or in this case, a server crashes), the entire performance stops.
"We've seen too many promising projects derailed by single points of failure," explains a DeepMind researcher familiar with the project. "A $5 cooling fan failure shouldn't scrap weeks of progress on a $10 million training run."
How DiLoCo Changes the Game
The new system organizes computing resources into independent "learning units" that operate like self-contained workshops. Each unit can complete multiple training cycles before sharing condensed updates with a central coordinator. This asynchronous approach means:
- No more waiting: Units don't sit idle while others catch up
- Failure resilience: One unit crashing doesn't stop the others
- Bandwidth efficiency: Only essential data gets transmitted between units
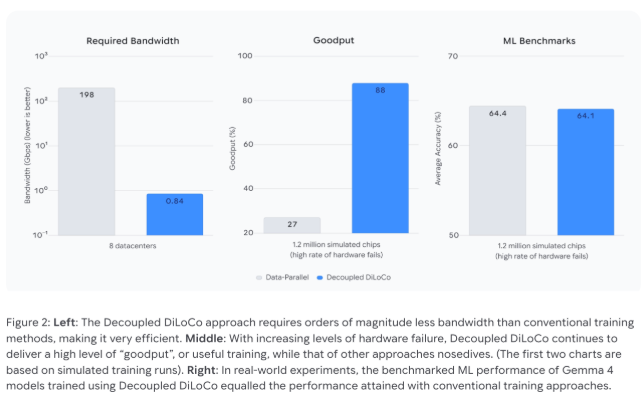
Test results demonstrate dramatic improvements. Where traditional methods collapse to 27% efficiency during hardware failures, DiLoCo maintains 88% utilization. The bandwidth reduction is even more striking - from needing specialized 198 Gbps connections down to just 0.84 Gbps, making global collaboration feasible over standard internet links.
Built-In Recovery Features
The system doesn't just tolerate failures - it actively works around them. During stress tests where all learning units were intentionally crashed, DiLoCo automatically resumed training as components came back online without losing progress.
Perhaps most impressively, the architecture supports mixing different generations of hardware in the same training run. Older TPU chips can contribute alongside newer models, potentially extending the useful life of existing infrastructure while easing transition periods during upgrades.
What This Means for AI Development
The implications extend beyond technical resilience:
- Cost savings: Less need for ultra-reliable (and expensive) hardware configurations
- Accessibility: Smaller organizations can participate in distributed training projects
- Sustainability: Better utilization extends hardware lifespan, reducing e-waste
- Global collaboration: Bandwidth reductions enable cross-border partnerships
As one engineer put it: "We're not just making AI training more robust - we're making it more democratic."
Key Points:
- 🛡️ Fault-tolerant design keeps training running through hardware failures
- 🌍 Bandwidth slashed from 198 Gbps to under 1 Gbps for global projects
- ♻️ Hardware flexibility allows mixing old and new equipment seamlessly
- 📈 Maintains 88% efficiency during failures versus 27% for traditional methods
