DeepMind's New Tool Peers Inside AI Minds Like Never Before
DeepMind Lifts the Hood on AI Thinking
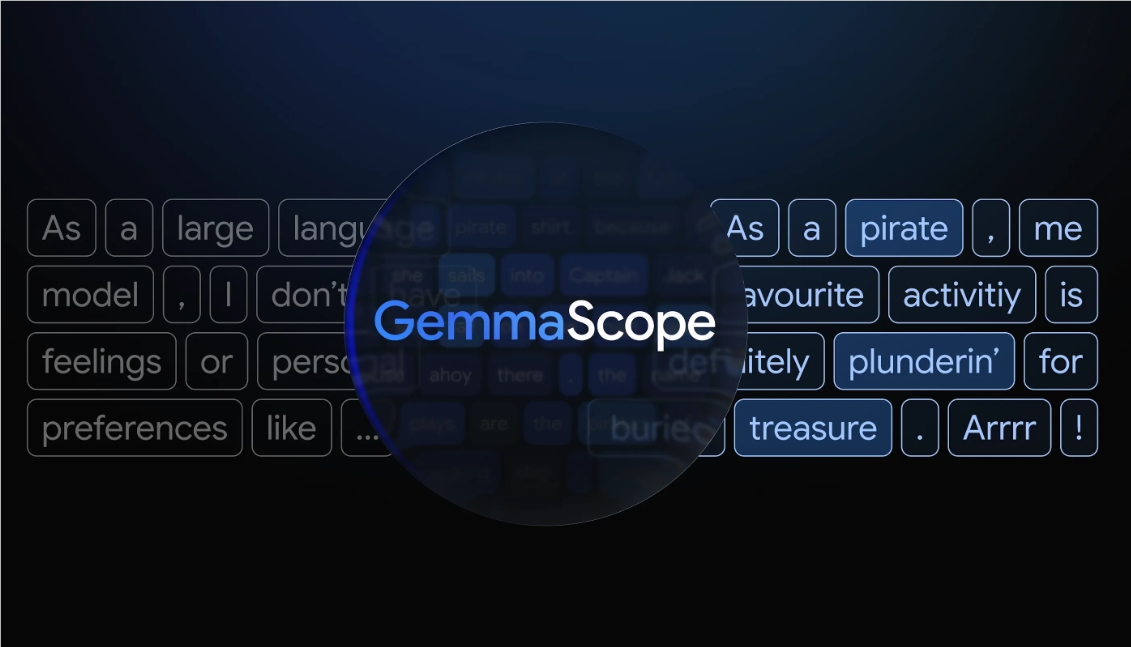
Ever wondered what really goes on inside an AI's "mind" when it responds to your questions? Google DeepMind's latest innovation might finally give us some answers. Their newly released Gemma Scope 2 toolkit provides researchers with powerful new ways to examine the inner workings of language models.
Seeing Beyond Inputs and Outputs
Traditional AI analysis often feels like trying to understand a conversation by only hearing one side of it. You see what goes in and what comes out, but the reasoning in between remains mysterious. Gemma Scope 2 changes this by letting scientists track how information flows through every layer of models like Gemma 3.
"When an AI starts hallucinating facts or showing strange behaviors, we can now trace exactly which parts of its neural network are activating," explains DeepMind researcher Elena Rodriguez. "It's like having X-ray vision for AI decision-making."
The toolkit works by using specialized components called sparse autoencoders - essentially sophisticated pattern recognizers trained on massive amounts of internal model data. These act like microscopic lenses that break down complex AI activations into understandable pieces.
Four Major Upgrades Over Previous Version
The new version represents significant advances:
- Broader model support: Now handles everything from compact 270-million parameter versions up to massive 27-billion parameter models
- Deeper layer analysis: Includes tools examining every processing layer rather than just surface features
- Improved training techniques: Uses "Matty Ryoshka" method (named after its developer) for more stable feature detection
- Conversation-specific tools: Specialized analyzers for chat-based interactions help study refusal behaviors and reasoning chains
The scale is staggering - training these interpretability tools required analyzing about 110 petabytes (that's 110 million gigabytes) of activation data across more than a trillion total parameters.
Why This Matters for AI Safety
The timing couldn't be better as concerns grow about advanced AI systems behaving unpredictably. Last month alone saw three major incidents where large language models produced dangerous outputs despite safety measures.
"We're moving from reactive patching to proactive understanding," says safety researcher Dr. Mark Chen. "Instead of just blocking bad outputs after they happen, we can now identify problematic patterns forming internally before they surface."
The open-source nature of Gemma Scope means independent researchers worldwide can contribute to making AI systems safer and more reliable - crucial as these technologies become embedded in everything from healthcare to financial systems.
The team has already used preliminary versions to uncover previously hidden patterns behind:
- Factual hallucinations
- Unexpected refusal behaviors
- Sycophantic responses
- Chain-of-thought credibility issues DeepMind plans regular updates as they gather feedback from the broader research community working with these tools. ## Key Points: 🔍 Transparency breakthrough: Provides unprecedented visibility into large language model internals 🛠️ Scalable solution: Works across model sizes from millions to billions of parameters 🔒 Safety focused: Helps identify problematic behaviors before they cause harm 🌐 Open access: Available publicly for research community collaboration