Claude 4.7 Dials Back the Bragging, Focuses on Getting Things Right
Anthropic Takes a Different Path with Claude 4.7
While competitors chase ever-higher intelligence scores, Anthropic made an unusual move with its latest Claude release. Version 4.7 arrived with an unexpected disclaimer: "This is not our most powerful model." Instead of pushing the boundaries of raw capability, the company focused on making an AI that fails less often and knows when to say "I don't know."
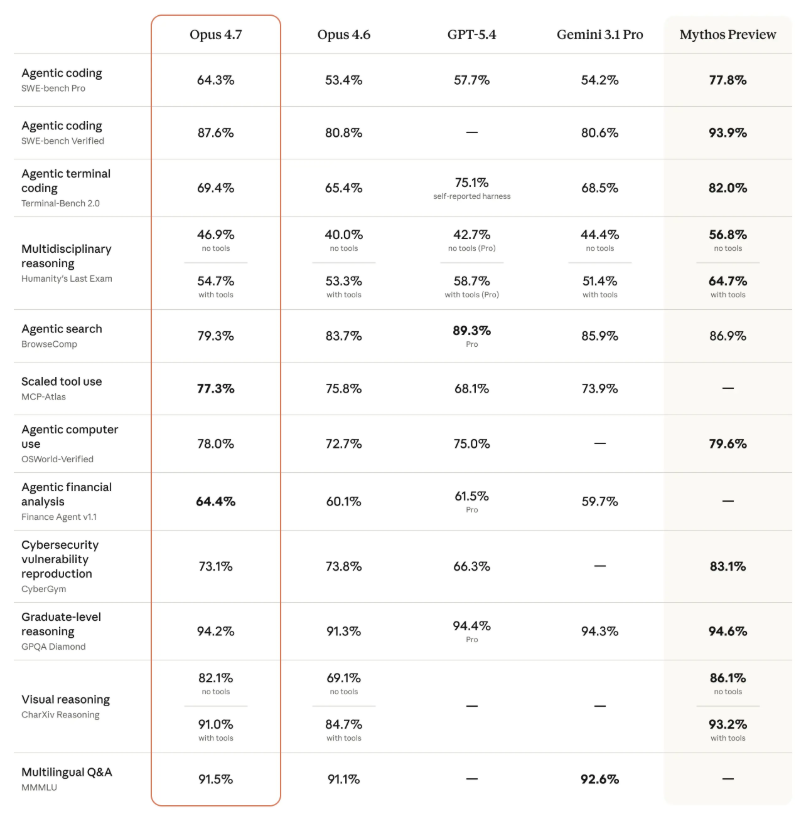
The Numbers Still Impress
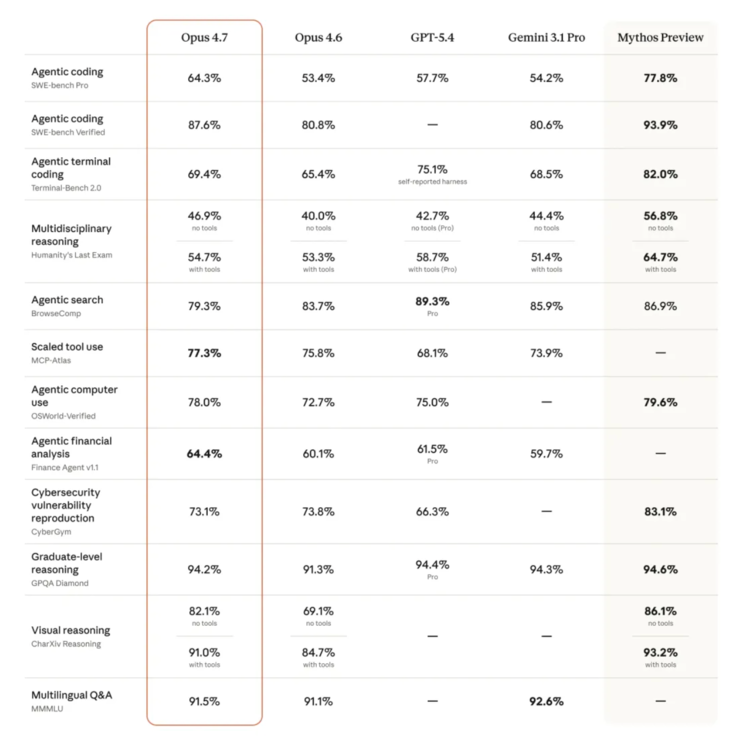
Don't mistake reliability for weakness. Claude 4.7 shows serious gains across key benchmarks:
- SWE-bench Pro (programming): Jumped from 53.4% to 64.3%, surpassing both GPT-5.4 (57.7%) and Gemini 3.1 Pro (54.2%)
- CharXiv (visual reasoning): Improved from 69.1% to 82.1% thanks to sharper image recognition
- Legal AI tasks: Nailed 90.9% on Harvey's BigLaw benchmark
The only notable dip came in search evaluations (83.7% to 79.3%), precisely because 4.7 refuses to guess when information is missing - a tradeoff many users will gladly accept.
A Changed Personality
Early adopters notice something different beyond the numbers. "It challenges me in technical discussions," says a Replit executive, "like a colleague who helps me make better decisions." Data platform Hex observed the model now admits data gaps rather than inventing plausible-looking numbers. When tools fail, 4.7 finds workarounds three times more often than its predecessor.
Vercel engineers spotted a fascinating new behavior: the AI now performs mathematical proofs before writing system-level code, showing unusual discipline for a language model.
The Cost of Reliability
This dependability comes at a price. 4.7 generates 1-1.35x more tokens for the same text and thinks longer on complex problems. Anthropic introduced new controls to manage these demands, including an "ultra-high intensity" thinking mode and budget tracking tools for developers.
Meanwhile, the rumored "Mythos" model remains in limited testing as "Project Glasswing," deemed too powerful for general release until safety evaluations complete.
Key Points
- Claude 4.7 prioritizes reliability over maximum intelligence
- Significant benchmark improvements despite more conservative approach
- Changed behavior includes admitting uncertainty and finding workarounds
- 35% higher token usage for more thorough processing
- Enterprise-only "Mythos" model still in testing
This release marks a fascinating shift in AI development - sometimes knowing your limits makes you more useful than being the smartest in the room.