Audio-SDS: Advanced Audio Generation Framework
Product Introduction
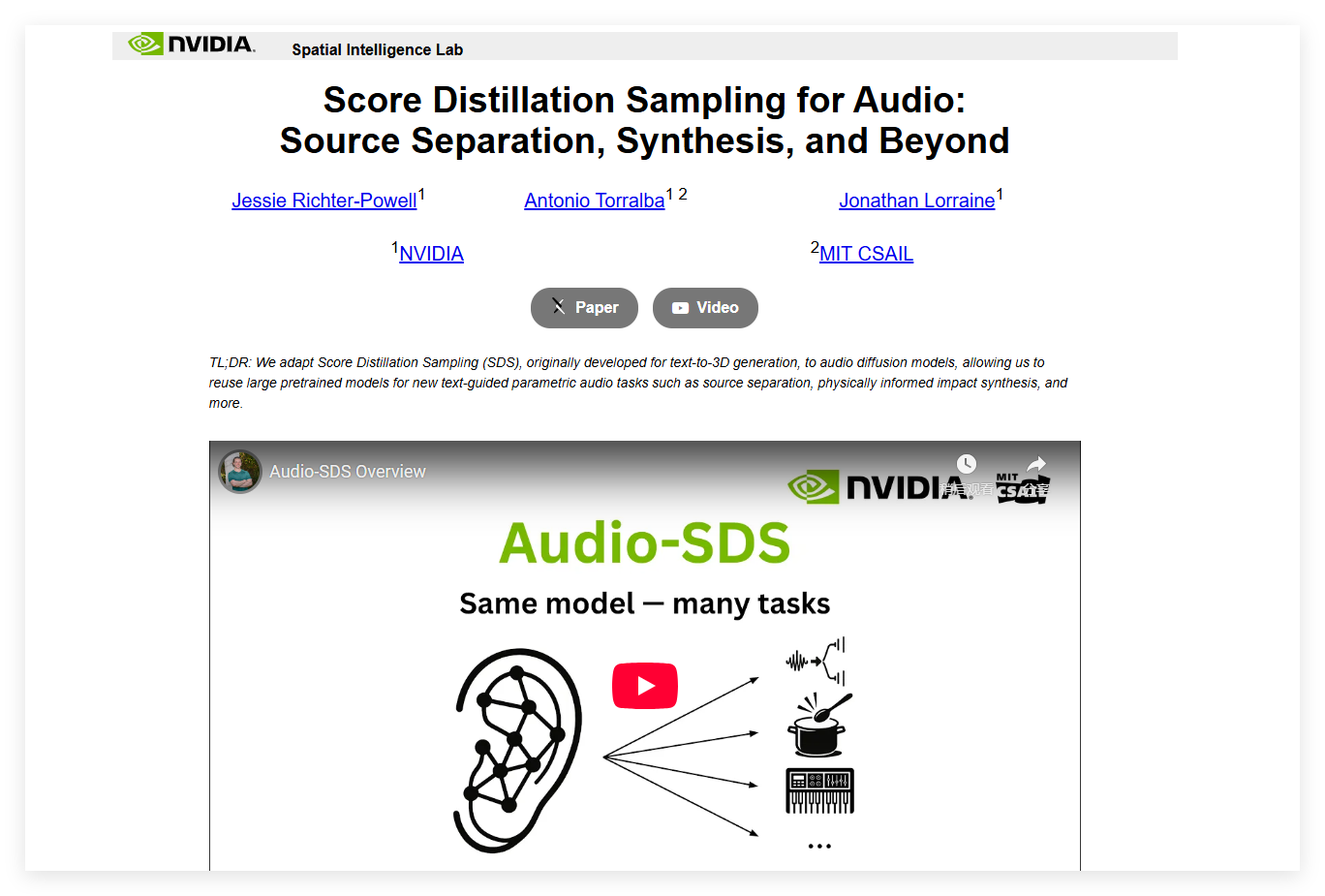
Audio-SDS revolutionizes audio processing by adapting Score Distillation Sampling for diffusion models. This framework tackles complex tasks like physical-guided sound synthesis and prompt-based source separation without requiring task-specific training data. By iteratively optimizing pre-trained models, it delivers professional-grade results for music production, sound design, and audio research.
Key Features
- Prompt-based source separation: Isolates individual audio components using simple text prompts
- Physics-guided synthesis: Generates realistic impact sounds for games and films
- FM synthesis optimization: Fine-tunes parameters for richer musical tones
- Zero-shot learning: Works immediately with pre-trained models, no additional training needed
- Real-time rendering: Produces audio results instantly based on user inputs
- Multi-task versatility: Handles instruments, environmental sounds, and voice processing
- Quality optimization: Uses backpropagation to continuously improve output fidelity
Product Data
- Architecture: Diffusion model with SDS enhancement
- Input types: Mixed audio files or synthesis parameters
- Output formats: Standard audio files (WAV, MP3)
- Processing: GPU-accelerated for real-time performance