Alibaba's New FIPO Algorithm Gives AI Models a Reasoning Boost
Alibaba's Breakthrough in AI Reasoning
Researchers at Alibaba's Tongyi Lab have developed a game-changing algorithm that helps artificial intelligence systems think more like humans. The new approach, called Future-KL Influenced Policy Optimization (FIPO), specifically addresses one of the biggest headaches in AI development: getting machines to recognize which pieces of information actually matter when solving complex problems.
Why Current Methods Fall Short
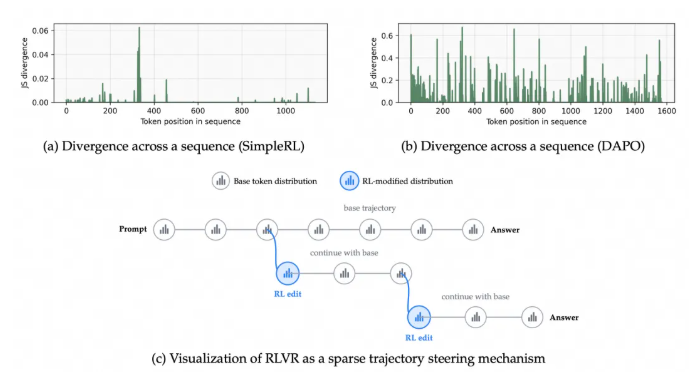
Traditional reinforcement learning techniques treat every piece of data equally when processing information chains - like giving equal attention to every word in a long sentence. "Imagine trying to solve a math problem where you can't tell which numbers actually affect the answer," explains one researcher. "That's essentially the challenge current models face."
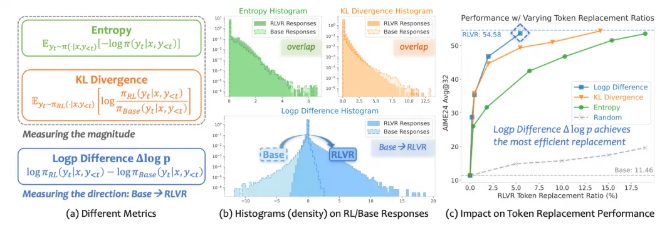
The team discovered that most tokens (the basic units of data processed by AI) show minimal changes during training, making it incredibly difficult for models to identify which ones are truly important. Standard evaluation metrics like entropy and KL divergence proved too blunt for this delicate task.
How FIPO Changes the Game
The breakthrough came when researchers introduced what they call the Future-KL mechanism. This innovative approach gives the AI system a way to "look ahead" and determine which pieces of information will have lasting importance for solving the problem at hand.
In practical terms, FIPO works by:
- Rewarding tokens that prove important for later reasoning steps
- Using a novel measurement called Δlog p (difference in log probability) to track meaningful changes
- Helping models maintain focus through longer reasoning chains without losing track
Real-World Performance
The results speak for themselves. When tested on the Qwen2.5-32B-Base model, FIPO enabled:
- Average reasoning lengths exceeding 10,000 tokens (far beyond previous limits)
- Significant accuracy improvements in complex mathematical reasoning
- Better performance than comparable models like o1-mini and DeepSeek-Zero-MATH
"What excites us most is how this solves the 'reasoning length stagnation' problem," says one team member. "It's like giving the model better working memory - it can now follow longer trains of thought without getting distracted or confused."
What This Means for AI Development
The implications extend far beyond mathematical problems. This advancement could lead to:
- More reliable AI assistants capable of complex multi-step reasoning
- Improved performance in fields requiring long-chain thinking like scientific research and financial analysis
- Better understanding of how AI systems process and prioritize information
The Tongyi Lab team continues to refine FIPO, with plans to explore applications in various domains where robust reasoning capabilities are crucial.
Key Points:
- 🚀 Future-aware learning: FIPO helps AI models identify information with lasting importance
- 📏 Length breakthrough: Enables processing of reasoning chains over 10,000 tokens long
- 🧮 Math mastery: Shows significant accuracy gains in complex mathematical problems
- 🔍 Better understanding: Provides new insights into how AI systems process information