Alibaba's New AI Brings Movie Dubbing to Life
A Breakthrough in AI Dubbing Technology
Imagine watching a dubbed film where the voices match the actors' lips perfectly, carrying just the right emotional weight - no more awkward mismatches or robotic deliveries. This vision is becoming reality thanks to Fun-CineForge, a groundbreaking open-source project from Alibaba's Tongyi Lab and University of Science and Technology of China.
Solving Hollywood's Biggest Dubbing Headaches
Traditional AI dubbing often falls short where it matters most. Remember that foreign film where the voice seemed disconnected from the actor's intense facial expressions? Or that animated series where characters sounded more like robots than living beings? Fun-CineForge tackles these issues head-on with two key innovations:
- The MLLM Dubbing Model goes beyond simple lip reading. It understands who's speaking, their emotional journey, and how they fit into each scene - much like a human director would.
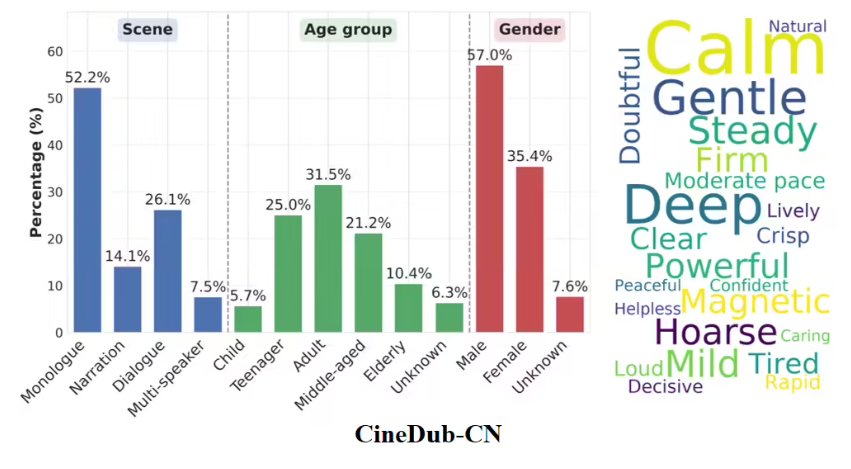
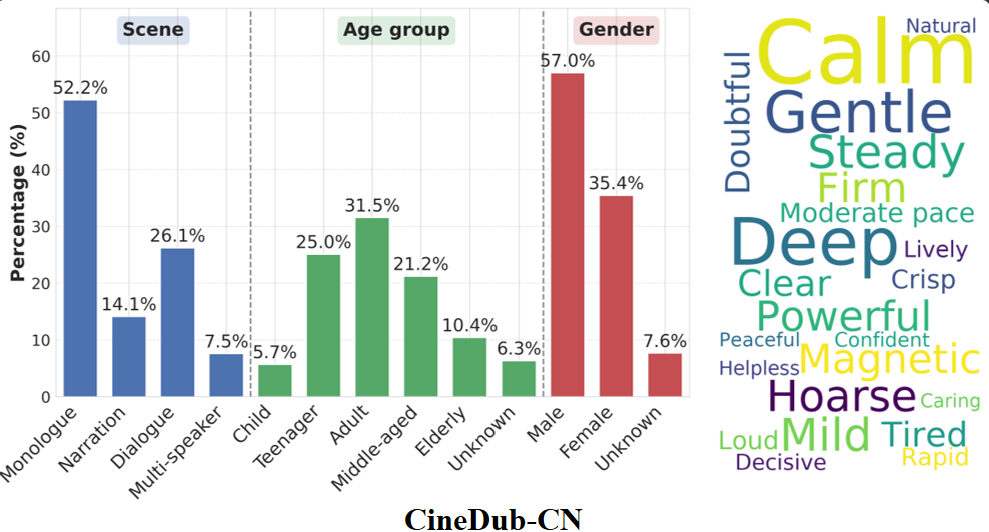
- The CineDub Dataset provides rich training material with diverse speech scenarios, from dramatic monologues to rapid-fire group conversations.
From Labs to Living Rooms: The Open-Source Revolution
The project timeline shows impressive momentum:
- Early 2026: Initial Chinese (CineDub-CN) and English (CineDub-EN) samples released
- March 16, 2026: Full model weights and inference code made publicly available on GitHub
- Current offerings include datasets from classics like China's "Dream of the Red Chamber" and Britain's "Downton Abbey"
When AI Meets Artistry
The real magic happens when technology understands performance. In tests with "Romance of the Three Kingdoms," Fun-CineForge didn't just replicate voices - it captured nuanced emotional arcs. Give it a "fear to resistance" clue, and it delivers a transformation that would make acting coaches proud.
This isn't just better text-to-speech. It's automated post-production with artistic sensibility - potentially slashing dubbing costs while raising quality standards worldwide.
Key Points:
- First multimodal AI system solving lip sync, emotion transfer and voice adaptation simultaneously
- Open-source model available now for developers via GitHub
- Includes unique Chinese/English datasets from popular TV series
- Demonstrated success in emotionally complex scenes
- Could revolutionize international film distribution