AI Coding Benchmarks May Paint Rosier Picture Than Reality
The Reality Check for AI Coding Assistants
That shiny benchmark score your favorite AI coding assistant boasts? It might not tell the whole story. Recent research from METR institution delivers a sobering message: the widely-used SWE-bench Verified benchmark could be overestimating AI programming capabilities by staggering margins.
When Automated Tests Meet Human Judgment
The study put five leading AI models - including Claude and GPT variants - through rigorous testing. Researchers submitted 296 pieces of AI-generated code to maintainers of popular open-source projects like scikit-learn and pytest. What they found challenges our reliance on automated benchmarks:
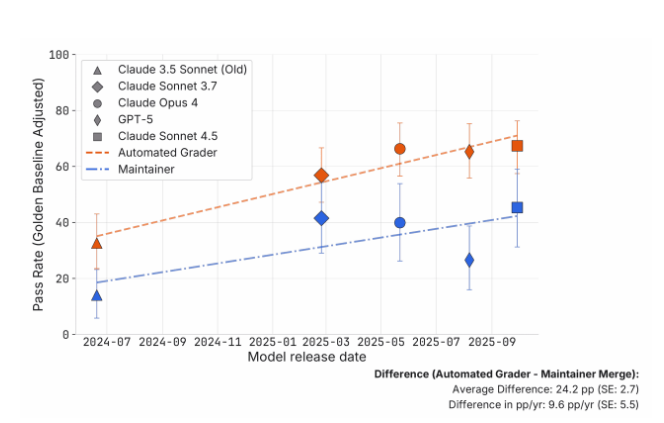
- 24 percentage point gap between automated scores and human approval rates
- Nearly half of "passing" solutions got rejected in real-world review
- Functional errors persisted even in code that cleared automated checks
The issues weren't just about style preferences either. Maintainers flagged three major problem areas:
- Code quality violations (failing project-specific standards)
- Structural disruptions (breaking existing code architecture)
- Fundamental functional errors (solutions that didn't actually work)
The Model Comparison Surprise

The research revealed fascinating patterns across different AI models:
- While Claude upgrades showed benchmark improvements, some versions introduced more functional errors
- GPT-5 surprisingly underperformed compared to Anthropic's models in this evaluation The most striking finding? That benchmark scores might inflate real capabilities by up to seven times. Where automated tests suggested Claude4.5Sonnet could complete tasks needing 50 minutes of human effort, maintainers' evaluations showed it would realistically require just 8 minutes.
Why This Matters for Developers
The implications extend beyond academic interest:
- Teams relying on AI coding assistants should temper expectations based on benchmark claims
- Current evaluation methods may not capture the nuances of real development workflows
- There's growing need for better testing frameworks that mirror actual engineering environments
The researchers emphasize this doesn't mean AI coding tools hit fundamental limits—just that our measurement systems need refinement. With better prompting strategies, iterative feedback loops, and more realistic testing scenarios, the gap between benchmarks and reality could narrow.
Key Points
- SWE-bench Verified may overestimate AI coding benchmarks paint rosier picture than reality