AI Breakthrough: New Architecture Supercharges Language Models Across Data Centers
The Computational Bottleneck in Modern AI
As artificial intelligence systems grow more sophisticated, they're hitting a wall - quite literally. The massive computational demands of today's large language models (LLMs) are overwhelming traditional data center architectures. Imagine trying to pour a gallon of water through a drinking straw - that's essentially the challenge facing AI developers today.
A Clever Division of Labor
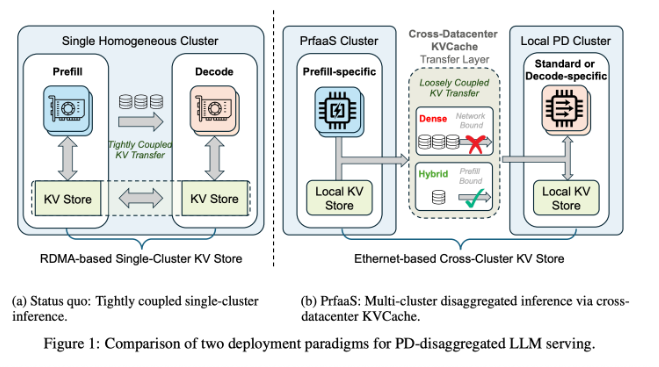
Moonshot AI, in collaboration with Tsinghua University, has proposed an elegant solution called Pre-filling as a Service (PrfaaS). The architecture recognizes that LLM processing naturally divides into two distinct phases:
- The pre-filling stage - where the model chews through input data (computationally heavy)
- The decoding stage - where it generates responses (memory bandwidth intensive)
"Current systems force both processes to happen in the same data center," explains Dr. Li Wen, lead researcher on the project. "It's like making a master chef both prepare ingredients and plate dishes in one cramped kitchen."
How PrfaaS Changes the Game
The breakthrough comes from separating these tasks geographically:
- Heavy lifting gets handled by specialized computing clusters optimized for number crunching
- Decoding occurs closer to end-users in local data centers
- The intermediate key-value cache (KVCache) travels efficiently over standard Ethernet networks
Early results are promising - 54% higher throughput compared to traditional approaches, with noticeable reductions in latency. In real-world terms, this could mean faster responses from your AI assistant even during peak usage times.
Smarter Resource Management
The architecture introduces clever innovations in resource allocation:
- A precise routing mechanism prevents traffic jams in data transmission
- Dual timescale scheduling dynamically adjusts to changing workloads
- Independent management of computing, networking, and storage subsystems
"What excites me most," says Dr. Chen from Tsinghua, "is how this scales. As new hardware emerges, we can plug it into the appropriate part of the system without redesigning everything."
The Future of AI Infrastructure
With AI applications expanding exponentially, solutions like PrfaaS couldn't be timelier. The approach not only addresses current limitations but provides a flexible framework for future innovations. As companies demand more from their AI systems - and users expect faster responses - this architecture might just become the new standard.
Key Points
- Problem Solved: PrfaaS overcomes computational bottlenecks in large language models
- How It Works: Separates pre-filling and decoding stages across optimized data centers
- Performance Boost: 54% higher throughput with reduced latency
- Smart Features: Advanced routing and dynamic scheduling prevent congestion
- Future-Proof: Designed to accommodate emerging hardware technologies


