小红书发布FireRedTTS-2,革新AI播客制作技术
小红书推出FireRedTTS-2推动AI音频技术发展
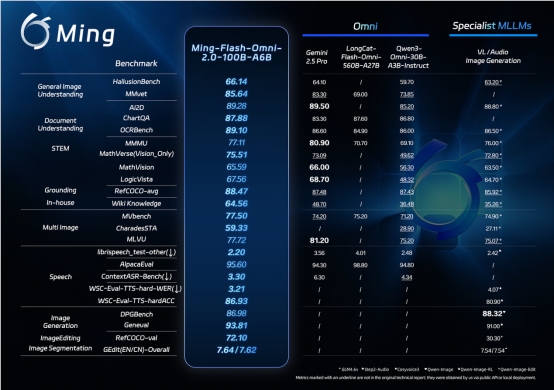
小红书智创音频技术团队正式发布FireRedTTS-2,这是专为AI播客制作设计的对话合成技术重大升级版本。新一代模型解决了当前解决方案在发音准确性、说话人切换稳定性和韵律自然度等方面的关键局限。
技术突破
升级架构包含以下特性:
- 增强的离散语音编码器提升音频质量
- 双Transformer模型实现连贯语音生成
- 低帧率处理技术使合成速度提高30%
- 多语言支持(中文、英文、日文、韩文、法文)
基准测试显示,FireRedTTS-2的自然度评分比行业标准高出15%,同时保持实时处理能力。
语音克隆创新
该模型的突出功能包括:
- 仅需单句样本即可克隆声音
- 保留说话人独特特征(音高、节奏、情感语调)
- 生成具有无缝切换的多说话人对话
这使得该开源方案成为Amazon Polly或Google WaveNet等专有系统的可行替代品。
实际应用场景
该技术支持:
- 配备类人主播的自动化播客制作
- 面向全球内容分发的本地化配音
- 非技术人员可操作的无障碍媒体创作
团队已在arXiv发布技术细节,并将代码库开源至GitHub。
未来发展路线图
计划中的增强功能包括:
| 功能 | 2026年第一季度目标 |
|---|
该技术有望通过向独立创作者提供专业级工具,颠覆32亿美元的语音合成市场。
核心优势:
✅ 工业级合成质量:无需专业录音设备即可产出录音室品质的播客音频 ✅ 成本效益显著:相比真人录制可降低高达80%的配音制作成本 ✅ 快速部署能力:仅需不到10秒样本音频即可实现声音定制