小红书开源多模态模型比肩顶级AI
小红书开源多模态模型挑战行业领导者
中国社交媒体平台小红书通过发布dots.vlm1进入AI竞赛,这是其首个自主研发的多模态大模型。该开源系统结合了12亿参数的NaViT视觉编码器和DeepSeek V3大语言模型,实现了与谷歌Gemini2.5Pro等专有模型相媲美的性能。

原生架构突破创新
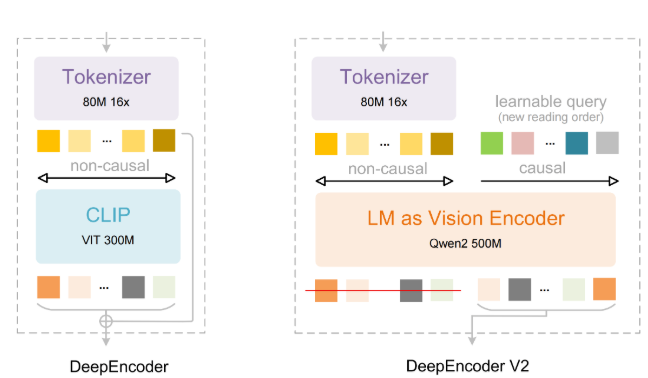
该模型的突出特点是其完全自主研发的架构,从零开始训练而非基于现有模型微调。NaViT编码器支持动态分辨率处理,能够更好地应对现实世界图像的多样性。通过结合纯视觉和文本-视觉训练的双重监督,该系统在处理非标准内容方面表现出色,包括:
- 表格和图表
- 数学公式
- 文档结构
"我们重建了整个训练流程," Hi Lab团队解释道,"从使用dots.ocr工具进行PDF处理的数据收集,到对网络来源文本的手动重写,每个组件都针对跨模态理解进行了优化。"
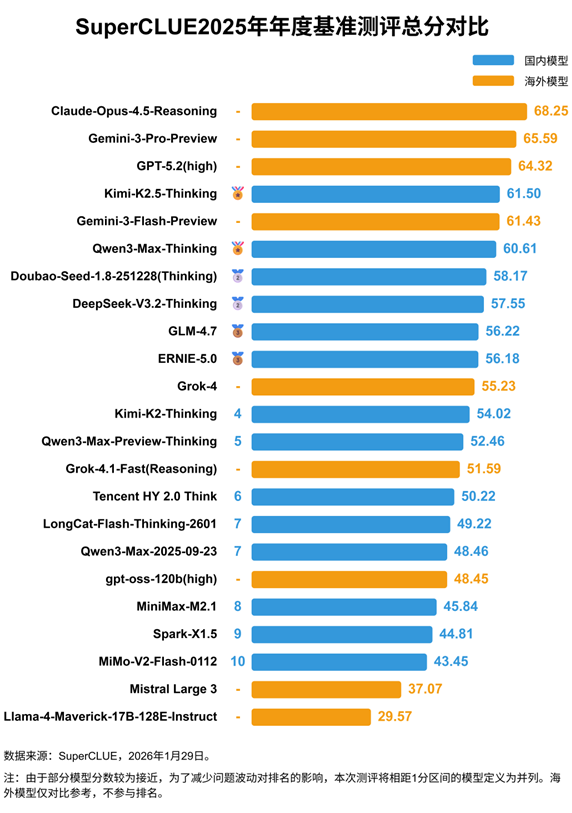
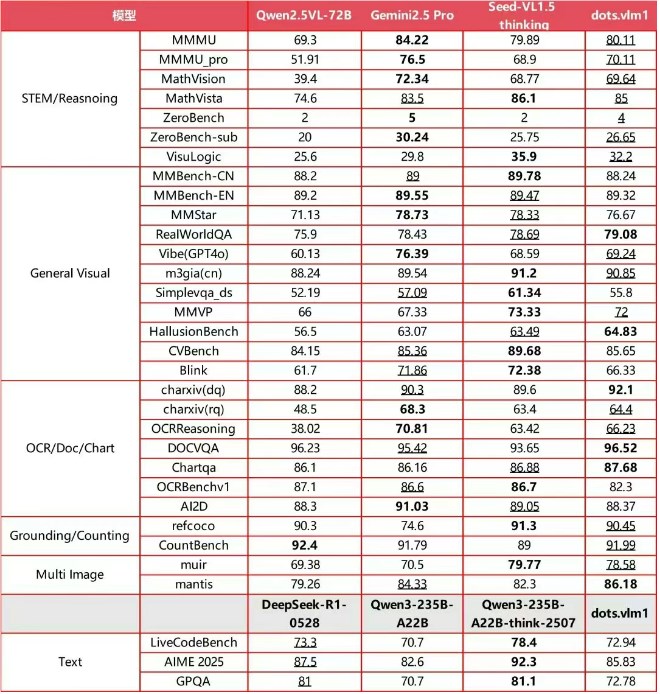
基准测试表现分析
在国际评估集的严格测试中,dots.vlm1显示出显著成果:
| 基准测试 | 性能水平 |
|---|
该模型在复杂分析任务中表现尤为突出,能够解决奥林匹克级别的数学问题并展现出强大的STEM推理能力。虽然在高级文本推理方面稍显不足,但其数学和编码性能与领先的大语言模型相当。
未来发展路线图
Hi Lab团队概述了未来发展的三个关键领域:
- 数据扩展:扩大跨模态训练数据集
- 算法增强:实施强化学习技术
- 推理改进:提升泛化能力
通过开源dots.vlm1,小红书旨在激发多模态AI领域的创新,同时确立自身在基础模型开发中的重要地位。
关键点:
- 小红书首个完整的开源多模态模型
- NaViT原生编码器天然支持动态分辨率
- 在6/8基准测试类别中与专有模型相当
- STEM和分析任务表现卓越
- 计划通过强化学习和数据扩展进行增强