全球AI对决:中国模型崛起,海外巨头仍占优势
中国AI模型与全球领先者的差距正在缩小
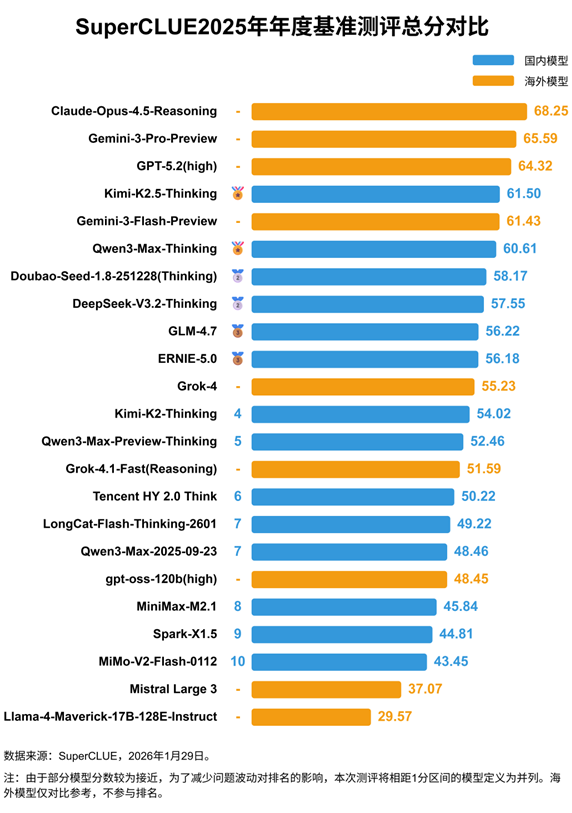
年度SuperCLUE基准测试已成为人工智能系统的奥林匹克竞赛。今年对23个顶级模型的评估生动展现了中文AI的现状与发展方向。
卫冕冠军
Anthropic的Claude-Opus-4.5-Reasoning以68.25分摘得金牌,在逻辑推理任务中表现尤为突出。紧随其后的是Google的Gemini-3-Pro-Preview和OpenAI的GPT-5.2(高配版),形成了分析师所称的中文模型"铂金梯队"。
"这些结果证实海外模型仍为综合理解能力树立标准,"清华大学AI研究员李伟博士解释道,"但差距缩小的速度超出所有人预期。"
中国新星崛起
真正的故事在于国内竞争者的快速进步:
- Kimi-K2.5-Thinking 以总排名第四并主导代码生成任务的表现令观察家震惊
- Qwen3-Max-Thinking 在数学推理上与Google表现相当——这一直被视为西方模型的强项
- 五款中国开源模型现已以显著优势超越国际同类产品
最说明问题的或许是这些进步出现的领域。"我们看到中国模型恰恰在最重要的领域——专业应用而非通用基准测试中取得领先,"科技分析师张越指出。
开源优势
报告强调了中国在开源AI开发领域日益增长的领导地位。国产模型占据了开源性能前十名中的七席,表明协作开发可能是中国的秘密武器。
"这不仅仅是追赶的问题,"阿里云工程师王涛表示,"在开放生态系统中,我们正在构建根本不同的东西——从长远来看可能更具可持续性。"
这些发现正值北京在中美持续贸易紧张局势下推动更大技术自主之际。
未来展望?
鉴于国产模型快速进步但整体仍处落后地位,行业观察家预测:
- 医疗和金融等垂直应用领域的竞争将加剧
- 中国科技巨头之间将建立更多战略合作伙伴关系
- 随着能力演进可能出现监管政策调整
这场竞赛似乎远未结束,但有一点似乎很明确:西方AI主导的时代可能已达顶峰。
关键要点:
- 🥇 Claude-Opus领跑全球排名但优势缩小
- 💻 Kimi主导编程领域,Qwen3擅长数学证明
- 🌐 中国开源生态系统成为全球领导者
- ⚡ 专业应用正成为新战场