语音编辑变得更简单:认识这款像编辑文本一样处理语音的AI
语音编辑革命:AI让语音修改变得像打字一样简单
想象一下,像编辑短信一样轻松调整某人的说话语调。这正是StepFun AI新推出的Step-Audio-EditX所承诺的,这个开源项目将彻底改变我们处理音频的方式。
超越语音克隆:精准控制时代来临
虽然现有语音系统可以模仿样本中的情绪和口音,但它们往往难以执行具体指令。Step-Audio-EditX通过将语音修改视为文本编辑来改变游戏规则——开发者只需简单命令就能调整情绪、风格甚至细微的声音特征。
秘诀何在?一种新颖的训练方法:使用相同词汇但不同声音质量的语音样本进行训练。"我们正在教会系统识别'愤怒'或'兴奋'的发音特征,"技术团队解释道,"这样它就能按需应用这些特质。"
工作原理:双码本遇见海量训练
该系统基于StepFun早期的音频研究成果构建:
- 两个专用分词器分别捕捉语言(16.7Hz)和语义(25Hz)信息
- 紧凑的30亿参数模型同时接受文本和音频数据训练
- 采用扩散变换器和BigVGANv2声码器进行高级重构
与传统系统有何不同?传统方法可能直接修改波形——就像在现有录音上作画。而Step-Audio-EditX更像文字处理,让你可以"选择"声音特质并"粘贴"到其他位置。
使其生效的训练技巧
团队采用了多项创新技术:
- 大间隔学习:使用表达相同词汇但呈现显著差异的三重语音样本进行训练
- 海量数据收集:涵盖60,000名多语言/方言使用者及专业配音演员录音
- 两阶段优化:先进行监督学习,再通过强化训练获得自然响应效果
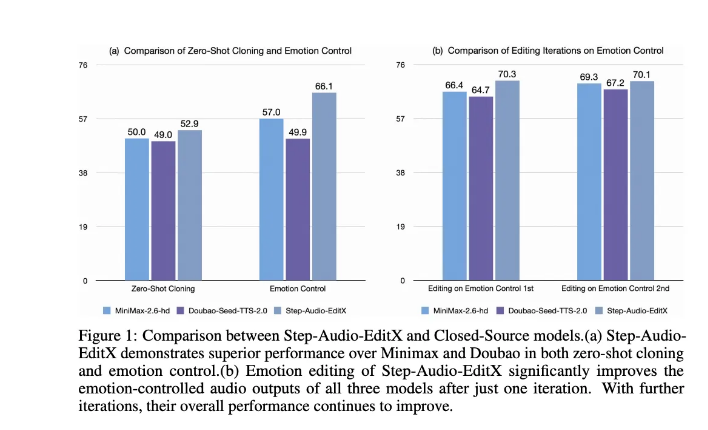
成果不言自明——在情绪/风格控制方面比现有方法准确率提升20-27%。
为何这项技术影响远超科技圈
其应用前景远超开发者工具范畴:
- 播客主可在录制后调整表达方式而无需重录
- 有声书朗读者可统一修改整章节的语速或语调
- 语言学习者能即时听到标准发音的各种变体 由于完全开源(包括模型权重),技术创新可能加速涌现。
团队视这仅为起点:"我们正进入一个声音不再只是被录制——而是被设计的时代。"
核心要点:
- 首个实现类文本编辑声音特质的系统
- 开源模型可处理情绪、风格和副语言特征
- 相较现有方法准确率显著提升
- 在媒体制作和辅助功能领域具有广泛应用前景




