谷歌Gemini 3.1 Flash-Lite:更快、更智能,但价格更高
谷歌最新AI模型:速度与智慧并存——但需付出代价
Google DeepMind推出了其最新的AI竞争者:Gemini 3.1 Flash-Lite。这款轻量级模型不仅速度快——还更聪明,在保持闪电般处理速度的同时实现了较前代版本的显著升级。

令人瞩目的性能表现
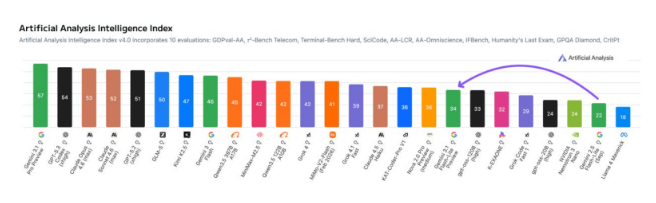
数据说明了一切。Gemini 3.1 Flash-Lite以每秒超过360个token的处理速度和平均仅5.1秒的响应时间,实现了速度与能力的双重突破。其行业基准测试智能得分跃升12点至34分,同时在Arena.ai竞争排行榜上获得1432 Elo评分。
该模型真正的亮点在于处理复杂任务的能力。在极具挑战性的GPQA Diamond测试中获得86.9%的分数,并在MMMU-Pro基准测试中达到76.8%的准确率,使其超越了Claude Opus和Kimi等重量级竞争对手。
灵活性与强大性能的结合
开发者通过本次发布获得了一个有趣的新工具——可定制的"思考深度"功能。这意味着同一模型可以通过调整信息处理深度,应对从快速翻译到构建复杂用户界面等各种需求。
进步的代价显现
但这些进步并不便宜。谷歌实施了大幅涨价:
- 输入token成本:现为每百万0.25美元(较之前有所上涨)
- 输出token价格:从每百万0.40美元飙升至1.50美元
近三倍的价格涨幅反映了平衡速度与复杂推理能力的发展阵痛。
对开发者的意义
该模型已通过Google AI Studio和Vertex AI平台开放测试。它的发布标志着行业转变——我们正在从单纯的价格战时代迈向高性能AI溢价定价的新阶段。
关键要点:
- 保持高速:每秒处理>360个token,响应时间约5秒
- 更智能的处理:各项基准测试中均取得显著智能提升
- 灵活应用:可定制深度适应不同复杂度需求
- 更高成本:定价近乎前代机型的三倍
- 市场转变:预示着向高性能溢价模型的转型