通义实验室突破性进展:好莱坞级AI配音触手可及
通义实验室发布颠覆性AI配音技术
想象一下观看外语电影时,配音不仅能完美匹配演员口型,还承载真实情感,并在复杂对话场景中始终保持角色声音的一致性。这一电影界的圣杯因通义实验室新开源的Fun-CineForge模型成为现实。
解决好莱坞最棘手的配音难题
传统AI语音在面对严苛的电影制作标准时往往表现平平。结果常常听起来机械生硬、错过情感线索或无法与屏幕上的口型同步。Fun-CineForge通过掌握四个关键维度正面解决这些问题:
- 口型同步魔法:模型逐帧分析嘴部动作以生成完美匹配的语音
- 情感智能:通过读取面部表情和导演注释来呈现细腻表演
- 声音一致性:即使在快速对话中角色也能保持独特的嗓音特征
- 精准计时:无论说话者是否可见,对话都能以毫秒级精度呈现
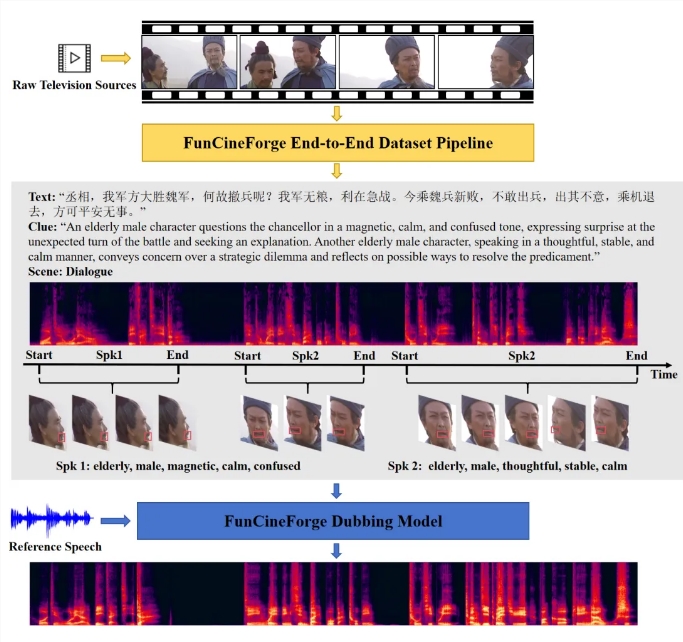
技术原理揭秘
突破来自两大关键创新:
- CineDub数据集 - 通过高级纠错技术将转录错误率降至仅1-2%的自动生成集合
- 四模态融合 - 结合视觉线索(口型动作)、文本指令(情感上下文)、音频参考(声音样本)和革命性的"时间模态"追踪,模型实现了前所未有的同步效果
"最令人兴奋的是它处理演员背对镜头的场景时的表现",项目首席研究员李文博士解释道,"传统系统在此类情况下表现糟糕,但我们的时间模态能保持一切完美对齐"
实际表现令人瞩目
早期测试显示Fun-CineForge在所有指标上均超越现有解决方案:
- 口型同步准确率提升40%
- 单词错误率降低35%
- 接近完美的声音一致性评分
该模型在处理多人对话时表现尤为突出——这项任务以往需要大量手动编辑才能完成。
开发者可通过以下平台获取Fun-CineForge:
核心亮点:
- 首个能逼真处理多角色配音场景的AI模型
- 引入革命性"时间模态"实现完美同步
- 开源特性加速影视行业采用进程
- 在提升本地化质量的同时降低后期制作成本