Tilde AI发布面向欧洲语言的开源大语言模型
Tilde AI发布开源语言模型 促进欧洲语言多样性
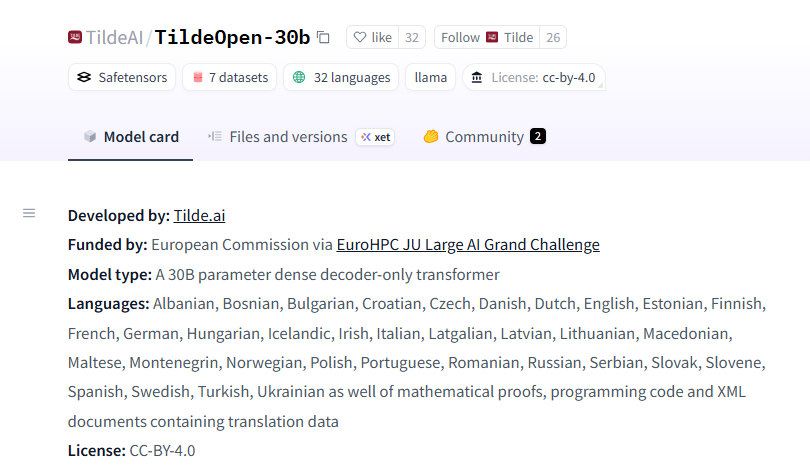
拉脱维亚语言技术公司Tilde正式推出TildeOpen LLM——一个专门为欧洲语言设计的开源基础大语言模型,尤其关注使用人数较少的地区性语言。该项目于2025年9月3日发布,标志着欧盟在推动语言公平性和数字主权方面取得重大进展。
技术规格与训练过程
这款采用密集解码器架构的30亿参数模型基于宽松的CC-BY-4.0许可协议,支持从拉脱维亚语、立陶宛语到乌克兰语、土耳其语等多种语言。训练工作在欧洲超级计算机LUMI(芬兰)和JUPITER上完成,总计消耗了欧盟委员会"大型AI挑战赛"提供的200万GPU小时计算资源。
技术实现采用了受EleutherAI启发的GPT-NeoX脚本,具体包含:
- 45万次参数更新
- 约20万亿已处理词元
- 三阶段采样方法:
- 跨语言的均匀分布采样
- 对高资源语言的天然分布增强
- 最终均匀扫描确保平衡性
关键架构特性包括:
- 60个网络层与6144维嵌入空间
- 48个注意力头
- 8192词元的上下文窗口
- SwiGLU激活函数
- RoPE位置编码
- RMSNorm层归一化
解决语言公平性挑战
传统大语言模型在处理波罗的海语系、斯拉夫语系等欧洲小语种时往往表现不佳,容易出现语法错误和不自然的表达。TildeOpen创新性地引入了"公平分词器",能够:
- 在词元空间中对所有语言进行均衡表征
- 通过减少词元数量提升效率
显著改善小语种的推理性能
该模型还允许组织在本地数据中心或符合欧盟标准的安全云环境中自主部署,既满足《通用数据保护条例》(GDPR)等数据保护法规要求,也解决了外国托管平台涉及的主权顾虑。
未来发展路线图
作为基础模型,TildeOpen将衍生出多个专用版本包括:
- 经过指令微调的变体
增强型翻译模型
该项目使拉脱维亚成为全球AI发展领域的新兴力量,同时有力推动了语言学多样性的保护工作。
核心亮点
🌍 多语言支持: 专注服务欧洲小众语言的独特需求 💻 欧盟本土训练: 依托欧洲超级计算机与先进采样技术 🔒 主权合规: 为组织机构提供符合GDPR的部署方案