腾讯为镜像站点辩护,回应OpenClaw数据抓取争议
腾讯因AI数据抓取行为面临强烈反对
OpenClaw创始人Peter Steinberger与中国科技巨头腾讯之间的公开争执引发了AI开发社区的广泛讨论。争议焦点在于:腾讯基于OpenClaw数据创建SkillHub平台时是否越过了道德界限。
指控内容
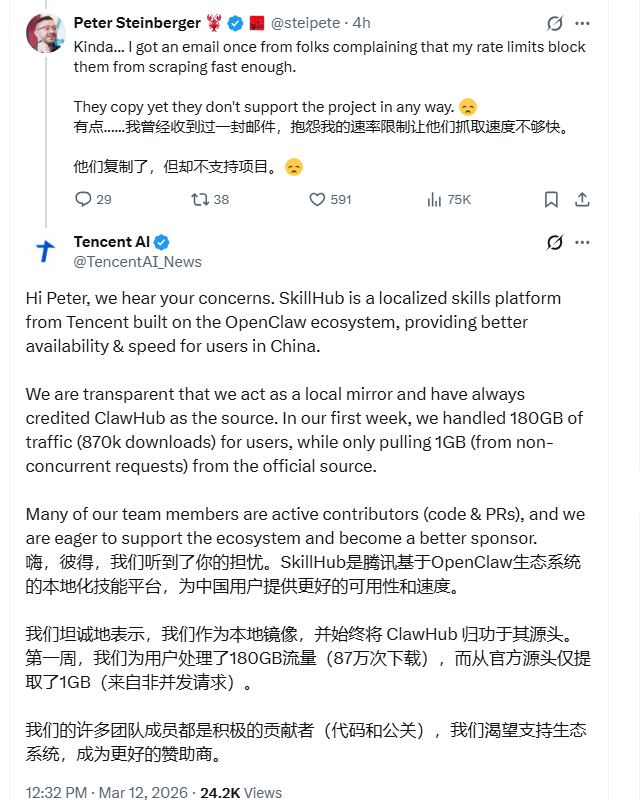
Steinberger在社交媒体平台X上发表了爆炸性言论。他写道:“腾讯未经授权抓取了我们整个ClawHub技能数据库。”更令他痛心的是发现部分腾讯员工曾抱怨ClawHub的访问速率限制影响了他们的抓取效率。
“他们完全复制了我们的项目,”Steinberger告诉粉丝,“却没有提供任何实质性的合作或支持。”
腾讯的辩护
该公司迅速通过其官方AI账号作出回应。腾讯将SkillHub描述为一个善意的解决方案,旨在帮助难以访问海外OpenClaw服务器的中国用户。
他们提供的数据耐人寻味:
- SkillHub首周处理总流量达180GB
- 实际从OpenClaw服务器获取的数据仅1GB
- 原平台带宽压力降低99.4%
“我们一直是开源社区的积极贡献者,”一位腾讯发言人表示,并补充说他们对未来的正式赞助协议持开放态度。
争议核心
这不仅仅是带宽统计数据的问题。Steinberger坚持认为正确的开源礼仪要求:
- 镜像项目前需进行明确沟通
- 通过双方协议获得官方认证
- 尊重开发者的署名权
“效率不应以透明度为代价,”他在后续帖子中强调。
更广泛的影响
这次冲突反映了AI淘金热中的成长阵痛。随着企业竞相围绕热门开源项目构建生态系统,开发者担心尽管创造了原始价值却会被碾压。
关键点:
- 腾讯创建SkillHub作为OpenClaw旗下ClawHub的中国镜像站点
- 开发者指控存在未经授权的数据抓取行为
- 腾讯声称其镜像站点实际上减少了原站点99%的流量
- 争议凸显企业规模化与开源伦理之间的紧张关系