Grok 4.20直击AI最大缺陷:捏造事实
xAI以全新Grok版本押注诚实
在这个痴迷于基准测试和速度的行业里,埃隆·马斯克的xAI正采取一种逆向策略。他们新推出的Grok 4.20模型优先考虑了许多用户希望其他AI能关注的一点:不胡编乱造。
真相重于性能
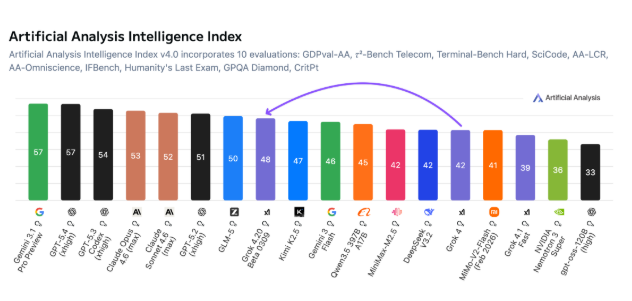
Artificial Analysis的独立测试揭示了Grok的独特优势:
- 78%的非幻觉率——有史以来最高记录
- 愿意说"我不知道"而非编造答案
- 在智力测试中得分较低(48分 vs 竞争对手57分)但在可靠性上胜出
"我们厌倦了模型假装成先知,"一位熟悉该项目的xAI工程师表示,"Grok知道自己的局限——这反而让它更有用。"
为不同需求打造
该模型提供三种模式:
推理模式 准确率冠军,创下最低幻觉记录,但速度较慢
标准模式 平衡日常对话和快速响应需求
多智能体模式 多个AI实例协同处理复杂任务
超越准确率的竞争优势
xAI不仅依靠诚实来推销Grok:
- 超大上下文窗口:可处理多达200万token(相当于整本书)
- 价格下调:每百万token 2-6美元,低于先前版本和竞争对手
该策略似乎针对那些错误答案比慢速响应代价更高的企业。正如一位分析师所说:"不是每家公司都需要莎士比亚——但没有公司想要一个骗子。"
此次发布标志着xAI从追逐通用人工智能转向解决实际企业问题。对于研究团队和数据敏感行业来说,Grok可能成为继OpenAI和谷歌之后的第三个可信选择。
关键点:
- Grok 4.20实现创纪录的低幻觉率(78%事实准确)
- 三种专用模式满足不同准确率/速度需求
- 超大上下文窗口(200万token)搭配竞争力价格(2-6美元/百万)
- 目标用户是优先考虑可靠性而非原始性能的企业