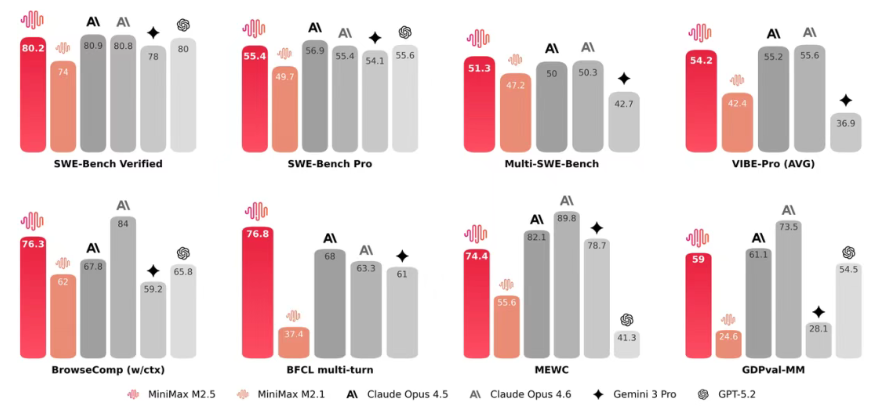
Step-Audio-R1.1 打破纪录,成为新一代语音AI冠军
StepZen 语音模型超越科技巨头
在开源 AI 领域的一项显著成就中,StepZen Star 公司的 Step-Audio-R1.1 语音推理模型在 Artificial Analysis Speech Reasoning 的全球评估排名中拔得头筹。该模型以前所未有的 96.4% 准确率击败了包括 Elon Musk 的 Grok、Google 的 Gemini 和 OpenAI 的 GPT-Realtime在内的闭源竞争对手。
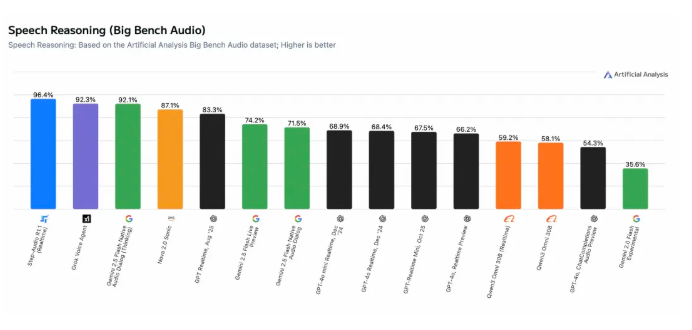
该模型的独特之处
Step-Audio-R1.1背后的突破性技术在于其能够无感知延迟地端到端处理语音——本质上像人类在对话中那样“思考”。与传统分段分析语音的模型不同,这项创新在生成回复的同时持续保持上下文连贯。
"我们教会了模型同时倾听和理解," StepZen首席研究员李文博士解释道,"当你与人交谈时,你不会等对方说完才开始理解——我们的模型复现了这种自然流程。"
令人印象深刻的实际应用
在产品发布演示中,与会者亲身体验了该模型的能力: -准确识别猫咪打架录音中的情绪语调 -在保留文化背景的前提下细致翻译韩国流行歌词 -在多人同时发言时保持连贯对话
该系统尤其擅长嘈杂环境下的表现,而这类场景通常会干扰传统语音AI的判断。
可用性与未来计划
研究团队已在HuggingFace(https://huggingface.co/stepfun-ai/Step-Audio-R1.1)公开权重参数,邀请全球开发者体验这项技术。对于非技术用户,StepZen通过其开放平台体验中心提供简化版服务。
展望未来,2027年2月将推出基于此技术的完整实时语音API。行业分析师预测这些接口可能彻底改变从客服到语言教育的多个领域。
关键要点:
- 破纪录准确率:96.4%评分超越所有主要竞争对手
- 类人处理机制:持续理解而非分段处理语音
- 即刻可用:HuggingFace提供开源权重及演示平台访问
- 即将推出:完整商业API计划于明年初发布