OpenAI加强ChatGPT安全防护,抵御隐蔽提示攻击
OpenAI强化ChatGPT防御机制应对人为操控
ChatGPT刚刚增强了抵御数字欺骗的能力。OpenAI宣布了重大安全升级,旨在阻止提示注入攻击——随着AI系统与网站和外部应用更深层次整合,这已成为日益严峻的问题。
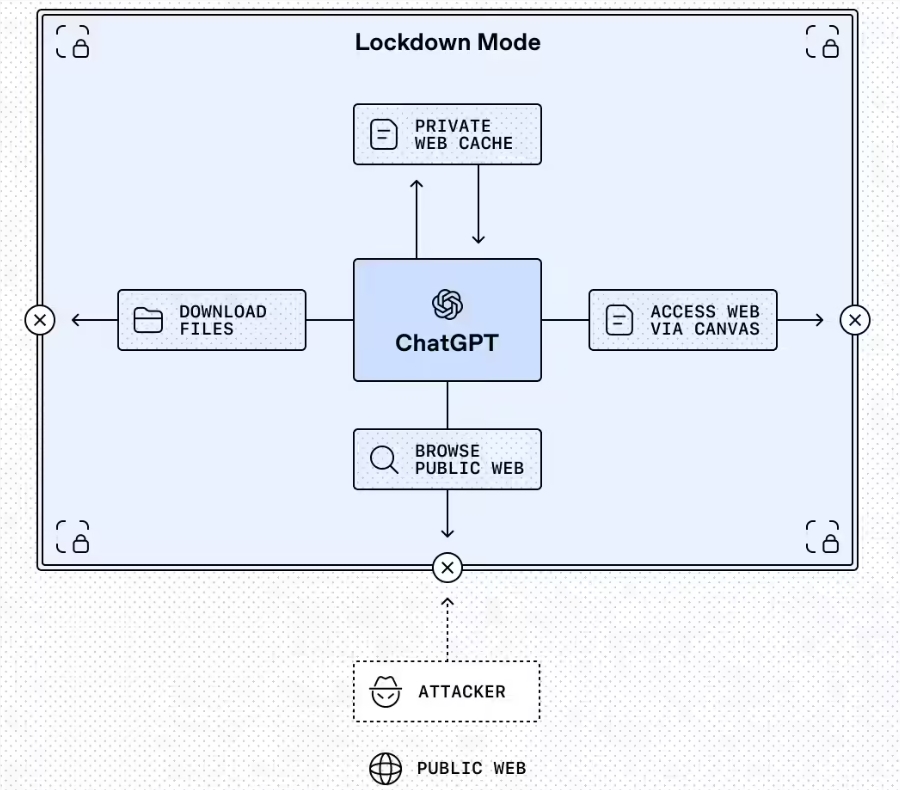
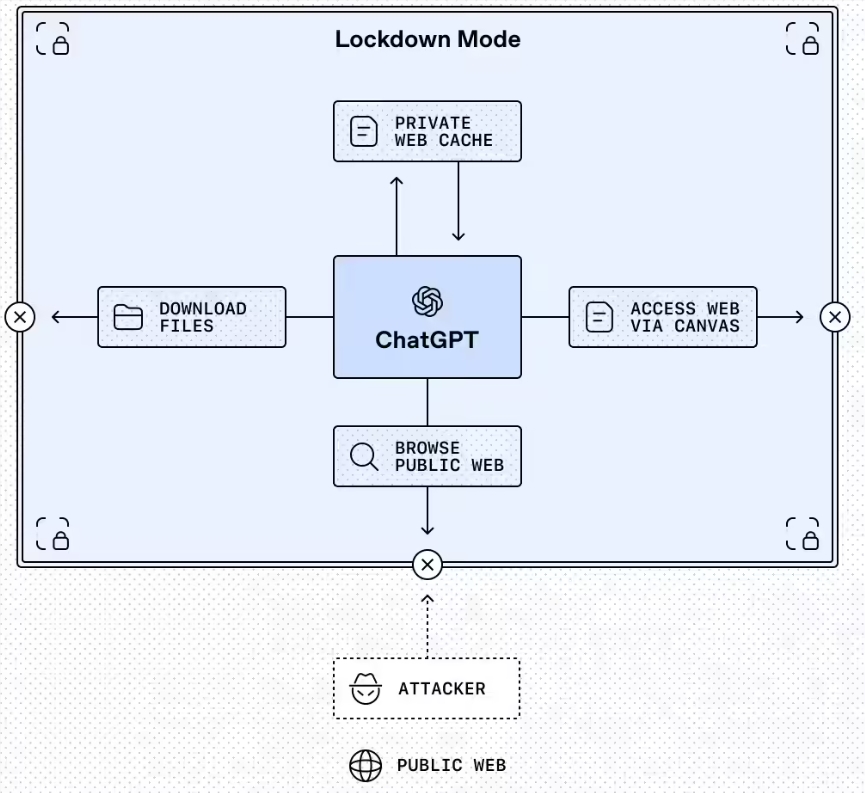
敏感交互的锁定模式
最突出的功能是锁定模式,这是一个可选设置,目前面向企业、教育、医疗和教师版本开放。可以将其视为ChatGPT在处理敏感数据时的'离线模式'。
"这不是普通的安防开关,"OpenAI在公告中解释,"锁定模式从根本上改变了ChatGPT与外界交互的方式。"
该模式通过以下方式工作:
- 将网页浏览限制在缓存内容范围内
- 禁用缺乏可靠安全保障的功能
- 为管理员提供对允许应用的精细控制权
公司计划在未来几个月将该模式扩展至消费者版本,同时推出新的合规API日志以帮助组织追踪使用情况。
高风险功能的明确警示标签
第二项重大变化是在ChatGPT、ChatGPT Atlas和Codex中引入了标准化的"高风险"标签。当用户激活可能危及安全的功能时,这些警告就会出现。
"某些功能虽然提升了实用性,但带来了行业尚未完全解决的风险,"OpenAI承认道。这些标签提供:
- 对潜在危险的清晰说明
- 建议的缓解策略
- 适用场景指南
当开发者启用网络访问或其他可能暴露隐私数据的功能时,这些警告尤为重要。
为何此时推出这些变更
这些更新正值企业越来越多地将AI系统与其内部工具和面向客户的应用程序连接之际。虽然这种整合释放了强大能力,但也创造了新的漏洞。
提示注入攻击可以通过精心设计的输入来操纵AI行为——可能诱骗聊天机器人泄露机密信息或执行未经授权的操作。近期全行业的多起事件凸显了这些风险。
OpenAI强调这些保护措施是对沙盒化和URL过滤等现有安全机制的补充而非替代。
公司建议管理员在启用锁定模式前仔细评估其安全需求,并指出其限制可能会影响一般使用场景下的功能性。
关键要点:
- 全新锁定模式严格限制高安全场景下的外部交互
- 标准化风险标签帮助用户在激活功能前了解潜在危险
- 防护措施针对操纵AI行为的提示注入攻击
- 更新目前适用于企业和机构版本,即将面向消费者推出
- 各项措施建立在现有沙盒化和数据泄露防护机制基础之上